
Persistent volumes
In Kubernetes, pods can be ephemeral: They can be created and destroyed multiple times during an application’s lifecycle. When a pod goes away, by default, any of the data within the pod goes as well.
Persistent volumes are for data that needs to remain past the lifespan of a pod. This is the data that needs to be included as part of any application’s backup. It is essential for ensuring data resilience and business continuity in a Kubernetes cluster.
You back up data from a persistent volume via snapshots, so you will want to ensure that your container storage interface (CSI) supports volume snapshots.
There are a couple of different options for the CSI driver that you choose. All of the major cloud providers have their respective CSI drivers.
For example, you may use VolumeSnapshot to take snapshots of PVs and PVCs utilizing AWS EBS volumes supported by CSI drivers. Kubernetes Volume Snapshots lets you create a copy of your EBS volume at a specific point in time. You can use this copy to return a volume to a prior state or to provision a new volume.
Regardless of which you choose, creating and restoring a snapshot follow the same steps:
- Create a volume snapshot class.
- Create the volume snapshot from an existing persistent volume claim (PVC).
Once you have a snapshot, you can use it to restore it to a different PVC using the snapshot as its source. This can require a lot of manual steps or coordination among the different moving parts. This is why Trilio identifies and creates these snapshots as part of the backup process. An aspect of this process is converting the snapshot to a QCOW2 image, an industry-standard format that enables features like malware scanning.
Custom resources
Custom resources are extensions in Kubernetes. They allow users to create custom objects alongside the core Kubernetes API objects.
In backup planning, identifying custom resources can be elusive, but it is necessary to create complete backups. Custom resources are often created when installing custom controllers or other applications. You must be able to identify and understand the relationships and dependencies among custom resources—some CRs may reference or depend on others.
Trilio will identify the custom resources tied to applications and controllers as part of the backup process.
Backup strategies
Now that we know what to back up, let’s explore various Kubernetes backup strategies. You may be managing multiple Kubernetes clusters or a single standalone Kubernetes cluster with multiple applications residing within it. Your backup strategy depends on how you run the workload and how you would like to restore the backups. You may choose application-centric backups, cluster-level backups, volume snapshots, or a combination.
Application-centric backups
In the “What to back up” section, we discussed using kubectl to save resource configs to YAML files. This process creates a lot of work and leaves room for human error, that can lead to applications not being fully backed up or be able to be restored.
To make the backup process easier, an application-centric strategy should be taken.
Application-centric backups use labels to group the entirety of the application. Because Kubernetes is an application-centric platform, you should know all the components that make up your application. A full application capture, including all components and resources, relies on the proper labeling of those resources.
Ensure that your application components are labeled with a unique identifier. You can then use labels to filter resources related to a specific application.
To label (annotate) a resource, use the annotate subcommand and provide a key=value pair:
$ kubectl annotate -n <namespace> pod/<pod-name> app=<application>
To list all the pods related to an application, use this command:
$ kubectl get pods -l app=<application>To list “all” the resources:
$ kubectl get all -l app=<application>Note that the command kubectl get all is misleading because it often does not list all resources related to an application. You often must build a custom resource list for your kubectl command to get all application-specific resources.
Trilio uses labels as part of its application-centric backup strategy to identify all the resources with the given labels and then determine any dependent resources. For example, if a deployment has an associated service account, it is also included in the backup.
Cluster-level information backup
You may take the approach of capturing cluster-level configuration separately from application-level configurations, so you can keep that information for any reference purposes during a new cluster build-out.
The following commands can be used to fetch cluster-level configurations:
- Cluster info: Use the following command to get general or detailed information about the Kubernetes cluster:
$ kubectl cluster-info $ kubectl cluster-info dump $ kubectl cluster-info dump --all-namespaces
- Nodes: Retrieve information about the nodes in the cluster, which includes details like node names, OS images, and kernel versions:
$ kubectl get nodes -o wide
You can also get the node’s labels and any taints applied to them that are the basis for the pod schedule:
$ kubectl get nodes -o=jsonpath='{range .items[*]}{"Node: "}{.metadata.name}{"\nLabels:\n"}{range .metadata.labels}{.}{"="}{.}{end}{"\nTaints:\n"}{range .spec.taints}{.effect}{":"}{.key}{"="}{.value}{end}{"\n\n"}{end}' - Kubeconfig file: Fetch the minified or detailed version of the kubeconfig file:
$ kubectl config view --minify $ kubectl config view --raw
- API resources: List the available API resources in the cluster:
$ kubectl api-resources
- API versions: List the API versions supported by the cluster:
$ kubectl api-versions
- Kubernetes version: Check the version of Kubernetes running on the cluster:
$ kubectl version
- Component status: Retrieve the health status of various Kubernetes components:
$ kubectl get componentstatus
- Kube-proxy config: View the configuration of the kube-proxy:
$ kubectl get configmaps -n kube-system kube-proxy -o yaml
- Kube-DNS config: View the configuration of Kube-DNS (CoreDNS):
$ kubectl get configmaps -n kube-system coredns -o yaml
These commands provide information about the Kubernetes cluster, its nodes, API resources, versions, and the health of various components.
Kubernetes namespaces
It is possible that a few applications and their supporting resources running in a particular namespace may be more crucial than any other application running on a separate namespace. This arrangement is particularly useful for scenarios where you want to create a backup of an isolated namespace, possibly before making significant changes or upgrades.
In this scenario, you may back up each resource deployed in a particular namespace.
You can use the following commands to back up an entire Kubernetes namespace:
- Export deployments, stateful sets, daemon sets, and replication controllers:
$ kubectl get deployments,statefulsets,daemonsets,replicationcontrollers,replicasets --namespace=$NAMESPACE -o yaml > deployments.yaml
- Export services:
$ kubectl get services --namespace=$NAMESPACE -o yaml > services.yaml
- Export ConfigMaps and secrets:
$ kubectl get configmap,secret --namespace=$NAMESPACE -o yaml > configmaps-secrets.yaml
- Export persistent volumes and persistent volume claims:
$ kubectl get pv,pvc --namespace=$NAMESPACE -o yaml > pv-pvc.yaml
- Export ingress resources:
$ kubectl get ingress --namespace=$NAMESPACE -o yaml > ingresses.yaml
- Export jobs and cronJobs
$ kubectl get jobs,cronjobs --namespace=$NAMESPACE -o yaml > jobs-cronjobs.yaml
- Export service accounts, roles, role bindings, and cluster roles:
$ kubectl get serviceaccounts,roles,rolebindings,clusterroles,clusterrolebindings --namespace=$NAMESPACE -o yaml > rbac.yaml
- Export custom resource definitions (CRDs):
$ kubectl get crds --all-namespaces -o yaml > custom-resources.yaml
GitOps for configuration
GitOps is a paradigm for implementing continuous delivery where the entire system state is represented as code and stored in a version control system—typically a VCS like Github or Bitbucket. In a “pull-based” GitOps model, the target environment actively pulls the changes from the Git repository.
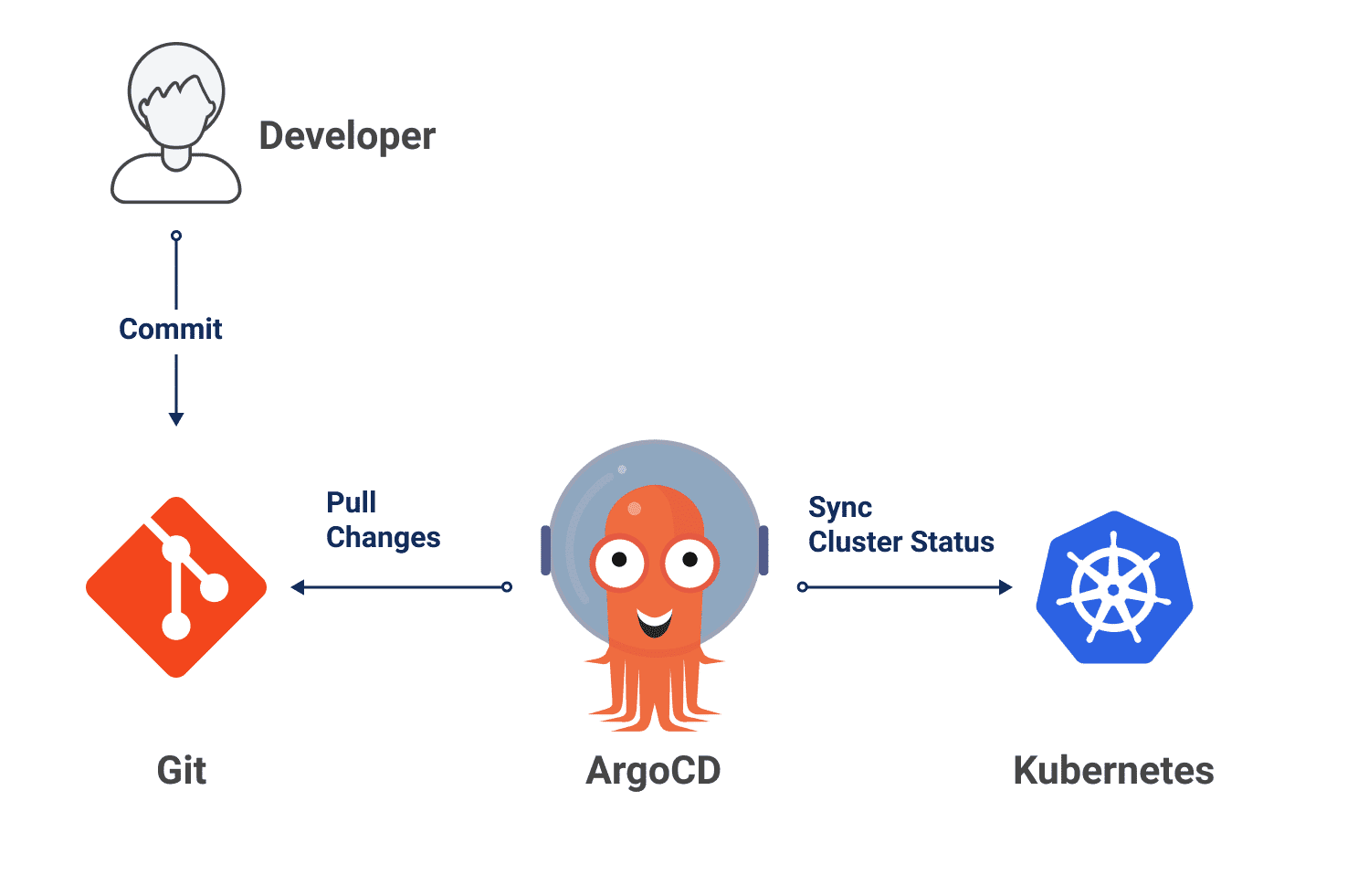
GitOps syncs Kubernetes with Git changes, making Git the source of truth for configurations (source)
The diagram above highlights another feature of a pull-based model: An agent or controller runs within the target environment. In this diagram, that agent is ArgoCD and continuously polls the Git repository for changes.
The agent within the target environment is responsible for comparing the environment’s current state with the desired state specified in the Git repository. If there are differences, the agent pulls the changes from the Git repository. The agent applies the changes to the target environment to align it with the desired state.
Using this strategy, your GitHub repo acts as a source of truth for your infrastructure and applications.
Scheduling regular backups
Scheduling Kubernetes backups is essential for several reasons, all of which contribute to the overall reliability, resilience, and recoverability of your Kubernetes clusters and applications.
Depending on the technology used, there are various approaches to scheduling your Kubernetes backup. Here are some examples.
- Using a native CronJob resource:
apiVersion: batch/v1beta1 kind: CronJob metadata: name: k8s--backup spec: schedule: "0 1 * * *" jobTemplate:
- Using custom scripting on a Unix system, you can create custom backup scripts using kubectl command and schedule them on a Unix system:
0 1 * * * /path/to/backup-script.sh
- With a third-party tool like Trilio, you can create a schedule policy:
kind: Policy apiVersion: "triliovault.trilio.io/v1" metadata: name: "sample-schedule" spec: type: "Schedule" scheduleConfig: schedule: - "0 0 * * *" - "0 */1 * * *" - "0 0 * * 0" - "0 0 1 * *" - "0 0 1 1 *"
Choose the method that best fits your requirements, considering factors such as simplicity, flexibility, and integration with your existing workflows.
Validating backups
Validating Kubernetes backups is crucial to ensuring that the backup data is consistent, reliable, and can be successfully used for recovery.
You should be able to list all available backups at any time, making it easy to manage and keep track of your backup history. There should also be a quick mechanism to validate your backups.
The backup validation process typically uses the same technology used to create the backup in the first place:
- Periodically perform full and partial restores from backups to ensure that the restore process is well-documented and effective.
- Use kubectl to validate the restored resources against the live cluster. Ensure that the restored resources match the expected configurations.
- Perform data integrity checks on application-specific data stored in ConfigMaps, secrets, and persistent volumes.
- If applicable, test the restoration of backups across different Kubernetes clusters or cloud environments.
Data restoration considerations
When restoring data from a backup, there are numerous considerations to be aware of. This is true whether the restoration is only partial (such as a namespace or specific application) or the entire cluster (such as you might do during a full disaster recovery process).
Data integrity
Ensuring data integrity during the Kubernetes restore process is critical to guaranteeing that the restored cluster accurately represents the original state.
This goes back to the validation process discussed above for regularly testing the integrity of the backups.
Documentation
It would be a mistake to consider documentation anything less than a crucial step in your backup/restore process. Documentation provides step-by-step procedures for the restoration process, and having documented procedures ensures that restoration is performed consistently across different environments and by different team members.
Keep the following in mind:
- Documentation acts as a disaster recovery playbook, providing guidelines, best practices, and a specific order of commands for restoring the cluster in the event of data loss, system failures, or other emergencies.
- In the case of restoration failures or issues, documentation serves as a troubleshooting guide. It includes insights into common problems, error messages, and potential solutions.
- If the restoration does not proceed as expected, documentation should include rollback procedures and guidance on how to revert to a previous state safely.
- Documentation is part of a feedback loop. Teams can review documentation after restoration incidents, learn from experiences, and continuously improve the restoration processes.
Cluster state
Understand the state of the cluster at the time of the backup. Ensure that any changes made after the backup are considered during the restore process. You may need to reapply configurations or changes that occurred post-backup.
Restoring the state of a Kubernetes cluster involves several considerations and potential challenges:
- Mismatched versions: Ensure that the version of the Kubernetes cluster state being restored is compatible with the version of the Kubernetes cluster you are restoring it to.
- Consistency checks: If the Kubernetes cluster state is backed up using etcd snapshots, perform consistency checks on the etcd snapshots to ensure the data’s integrity.
- Configuration drift: Changes in the cluster configuration over time can lead to drift. Ensure that the restored state aligns with the current configuration requirements and settings.
- Namespace restoration: Make sure that namespaces and their associated resources are restored correctly. Validate that role-based access control (RBAC) configurations for each namespace are intact.
- Network policies: Confirm that network policies are restored correctly. Validate that communication between pods adheres to the defined policies.
- Storage class and PV/PVC bindings: Verify that the storage classes used in the backup are compatible with the target environment and that the bindings between PVs and PVCs are preserved during restoration.
- Integration with external systems: If the cluster interacts with external systems (e.g., external databases or authentication providers), ensure that these integrations are considered and validated.
Control plane components
If you are restoring the control plane, be prepared to reinstall or reconfigure the Kubernetes control plane components, including the API server, controller manager, and scheduler. The configuration for these components may need to be adjusted to match the restored state. Do not miss the following considerations:
- Configuration parameters: Verify the configuration settings of the controller manager and scheduler. Ensure that any custom flags or parameters are applied correctly during the restoration.
- Kubeconfig files: Ensure that kubeconfig files for control plane components are updated and reflect the restored state. Validate that authorization policies, including RBAC, are consistent.
- Admission controller configuration: If the control plane components use admission controllers, verify that the configuration is consistent. Changes in admission controllers can impact the validation and mutation of API requests.
- Cluster identity and certificates: Each control plane component, including the API server, controller manager, and scheduler, should have a unique identity. Certificates should be regenerated or managed appropriately, including the certificate authority (CA).
Specifically for the API server, consider the following potential pain points:
- Service account configuration: Check that service account and token settings, including token expiration policies, are consistent with the original configuration.
- RBAC and authentication providers: If the API server configuration includes RBAC and authentication provider settings, validate that these settings align with the intended security policies.
- Admission controller configuration: Verify that the admission controller configuration is consistent. Changes in admission controllers can impact the validation and mutation of API requests.
Cluster networking
Kubernetes networking is the base of the ecosystem upon which the entire backup strategy rests. It is important to consider the networking configuration, including network policies, service objects, and any network-related settings. Ensure that the following points are addressed before or during the restoration process:
- CNI plugin compatibility: Ensure that the Container Network Interface (CNI) plugin version used in the restored cluster is compatible with the Kubernetes version.
- Consistency with pod CIDR: If the cluster uses a specific pod CIDR range, ensure that the restored cluster has the same pod CIDR to avoid conflicts with existing IP allocations.
- Consistency with service CIDR: Like the pod CIDR, maintain consistency with the service CIDR range. This is important for service discovery and communication.
- Node network settings: Verify that the networking configurations on individual nodes (e.g., iptables rules) are consistent with the original setup. Inconsistencies can impact pod-to-pod communication.
- Policy definitions: If the cluster uses network policies, ensure that the policy definitions are restored correctly. Changes in network policies can affect the communication rules between pods.
- Ingress configuration: If the cluster uses ingress controllers or load balancers, ensure that their configurations are restored. This includes settings for routing and load balancing external traffic to services.
- DNS settings: Verify that the Domain Name System (DNS) configuration is consistent. DNS is critical for service discovery, and any inconsistencies can lead to resolution issues.
- Firewall settings: If the cluster operates in a cloud environment, ensure that firewall rules or security groups are configured to allow the necessary traffic between nodes and services.
- Internet access: If pods require external internet access, make sure that the necessary configurations are in place. This includes proxy settings or any specific configurations required for external access.
- Overlay network protocols: If the cluster uses an overlay network (e.g., Flannel or Calico), ensure that the chosen network protocol is supported and consistent across nodes.
- Load balancer settings: If external load balancers are used, verify that their configurations, including backend pools and health probes, are restored correctly.
- IPv6 compatibility: If IPv6 is in use or supported, ensure that the restored cluster maintains compatibility with IPv6 settings.
Disaster recovery: Restoring a full backup
Restoring a Kubernetes cluster from a backup involves recovering the cluster’s state, configurations, and application data to a specific point in time. During disaster recovery, you will typically be doing a full restore rather than a partial restore or a namespace- or application-specific restore.
There are a few steps that you must follow for a successful restore from backup. These steps may vary based on the technology that you have chosen to restore:
- Ensure that the backup files or snapshots are available and accessible. This may include backups stored locally, in cloud storage, or placed in other designated repositories.
- Verify that the cluster is in a stable state and can be safely restored when you have chosen to restore to an existing cluster. Ensure that the necessary infrastructure, networking, and storage resources are available. You may choose to define a few critical workflows within your Kubernetes cluster to ensure that your cluster works as intended. These workflows can be automated to avoid unnecessary repetition and the risk of human error.
- If necessary, prepare the control plane components, including API servers, etcd, and controller managers, for restoration. You may need to recreate the control plane components using the restored data. This may involve applying configuration files, manifests, or infrastructure as code (IaC) scripts. Ensure that worker nodes are available and can be restored to the desired state. Apply configurations or scripts to recreate worker nodes if necessary.
- Deploy applications and workloads to the restored cluster. This may involve applying deployment manifests or Helm charts. Verify that application configurations match those in the backup. Apply configurations and secrets necessary for the proper functioning of the cluster, including Kubernetes configurations, service account tokens, and any custom configurations.
- Conduct any necessary post-restoration activities, such as updating DNS records, reconfiguring load balancers, or adjusting network settings.
Rather than doing all of the above manually, you can use a third-party tool to do most of these steps (if not all) automatically for you. As an example, to restore a backup from the third-party tool Trilio, the following manifest can be used:
apiVersion: triliovault.trilio.io/v1
kind: Restore
metadata:
name: app-restore
spec:
source:
type: Backup
backup:
name: mysql-label-backup
namespace: default
skipIfAlreadyExists: true
This command will find the backup within the configured secured storage location, write-lock that location for any further writes, and perform the restoration into the desired namespace.
Restore state-critical applications
You may require a turnkey solution that can be leveraged to redeploy all apps from their last captured running states rather than working with the application team to deploy their applications at another site. This problem gets amplified when you deal with applications and services at scale.
Furthermore, stateful applications also need data volumes to connect to the metadata configuration, so a solution may be needed that can capture application-consistent point-in-time metadata and data for DR.
There are tools available like Trilio that allow users to restore multiple applications or namespaces as part of a single workflow to restore business operations. It is possible to create and execute various DR plans for different tiers of applications based on criticality from multiple targets or backup locations. The DR plan is created and saved at the destination cluster, which means that the plan can be executed even when the source cluster is not available.
Data loss risk
There is always a risk of losing data; some data may be lost if there were significant changes post-backup. Reduce the potential for this gap by creating backups frequently.
Challenges and best practices
Kubernetes backup comes with its own set of challenges. To overcome them, consider the following best practices.
Emphasize data consistency
Maintaining data consistency between the backup and the primary data store is a significant challenge. Inconsistent data can lead to issues when restoring from backups. To address this challenge, consider techniques like quiescing applications (temporarily pausing data writes) and utilizing storage snapshots for more accurate backup snapshots.
If the data is being stored in an external database, you can adopt practices like having a read-only copy of your database that is in synchronous replication with the primary database. This ensures an up-to-date backup of your database without impacting existing database performance.
Ensure compliance and use data encryption
Ensure that your backup and recovery solutions comply with data privacy and security regulations. Encrypt sensitive data both in transit and at rest to safeguard against breaches. This is especially important if your organization operates in regulated industries or handles sensitive customer data. Adopt practices like the following:
- Employ cluster hardening measures like CIS Kubernetes Benchmarks.
- Enforce RBAC to control access and assign least privilege access to users.
- Regularly scan container images for vulnerabilities using image scanning tools such as Clair.
- Enable Transport Layer Security (TLS) for communication between Kubernetes components. Use TLS certs to secure communication between nodes, the API server, and other components.
- Implement encryption at rest for sensitive data stored in etcd. This involves setting up encryption options in the etcd configuration file.
- Set up mutual TLS (mTLS) authentication between the Kubernetes API server and etcd. This ensures that both parties authenticate each other, enhancing security.
- If the Kubernetes service runs on a cloud provider (managed service), leverage cloud-native encryption solutions provided by the cloud platform, such as AWS Key Management Service (KMS) or Azure Key Vault.
Pay attention to version compatibility
Kubernetes is a rapidly evolving ecosystem with frequent updates and changes. Ensuring that your Kubernetes cluster is continually upgraded to the latest version is crucial for security, bug fixes, and access to new features:
- Regularly monitor official Kubernetes release announcements and release notes.
- Kubernetes has multiple release channels, including stable, preview, and alpha releases. Consider using the stable release channel for production clusters and preview or alpha channels for non-production environments.
- Understand the Kubernetes version skew policy, which defines the compatibility between different components in a cluster.
Any major changes in your Kubernetes version should also be followed by a fresh backup to maintain version compatibility between live data and the backup.
You should always ensure that your backup and recovery tools are compatible with your Kubernetes version. Regularly update your backup solutions to stay in sync with the latest changes in Kubernetes.

