
Real-life use cases
Here, we explore a few use cases where disaster recovery is essential in Kubernetes. These scenarios reflect common and significant issues that Kubernetes administrators and engineers often encounter.

The use cases for having a Kubernetes disaster recovery plan (source: Trilio)
Kubernetes ransomware protection
In the face of rising cyber threats, particularly ransomware, Kubernetes environments demand robust protection. According to some estimates, ransomware attacks have increased as much as 13%, with an average cost of around 1.85 million and an average downtime of 22 days, highlighting the growing threat landscape.
A comprehensive disaster recovery tool or strategy should encompass several vital aspects for counteracting ransomware threats in Kubernetes environments:
- Immutable backups: Integration with backup repositories like S3-supported storage is essential for creating “object-locked” backups. This feature ensures that backups remain unaltered, providing immunity against ransomware modifications.
- 360° application protection: A strategy aligned with the NIST Cybersecurity Framework is necessary for complete protection, covering everything from identifying vulnerabilities to recovering applications. To bridge together multiple tools, your backups should be in a standard format such as QCOW2.
- Rapid recovery: The ability to quickly restore operations is crucial. Easy, one-click workflows facilitate quick recovery, significantly diminishing the likelihood and impact of ransomware attacks. This includes reducing the need to consider paying for ransomware.
Trilio is well-equipped to address these crucial aspects of ransomware protection in Kubernetes. It supports immutable backups, uses the QCOW2 image format for easier integration with security scanning tools, and enables rapid recovery of your data. Its full suite of features and capabilities aligns with best practices, offering a robust solution for maintaining the integrity and availability of applications in the face of cyber threats.
Kubernetes cloud infrastructure outages
Infrastructure or hardware failures, though infrequent in today’s cloud Kubernetes environments, can have severe consequences when they occur. This use case addresses the critical role of the disaster recovery process in Kubernetes environments, particularly in the context of infrastructure or hardware failures. In Kubernetes environments, infrastructure or hardware failures present distinct challenges:- Amplified Impact Due to Interconnected Services: In Kubernetes, the failure of critical infrastructure components can trigger widespread system disruptions. Given the platform’s reliance on a mesh of interconnected services and applications, a single point of failure can lead to cascading effects, impacting a range of services and applications beyond the initial failure point.
- Complex Recovery Requirements: Production Kubernetes environments are often complex, with multiple layers of configurations, services, and dependencies. Recovering from a hardware failure is not just about restoring data; it involves re-establishing network configurations, service connections, and various application dependencies. This complexity requires a detailed and well-coordinated recovery process to ensure all components are correctly reinstated.
- Heightened Risk for Critical Operations: Many businesses rely on Kubernetes for their critical operations and applications, making infrastructure outages a significant risk to vital operations and potentially leading to service-level agreement (SLA) violations.
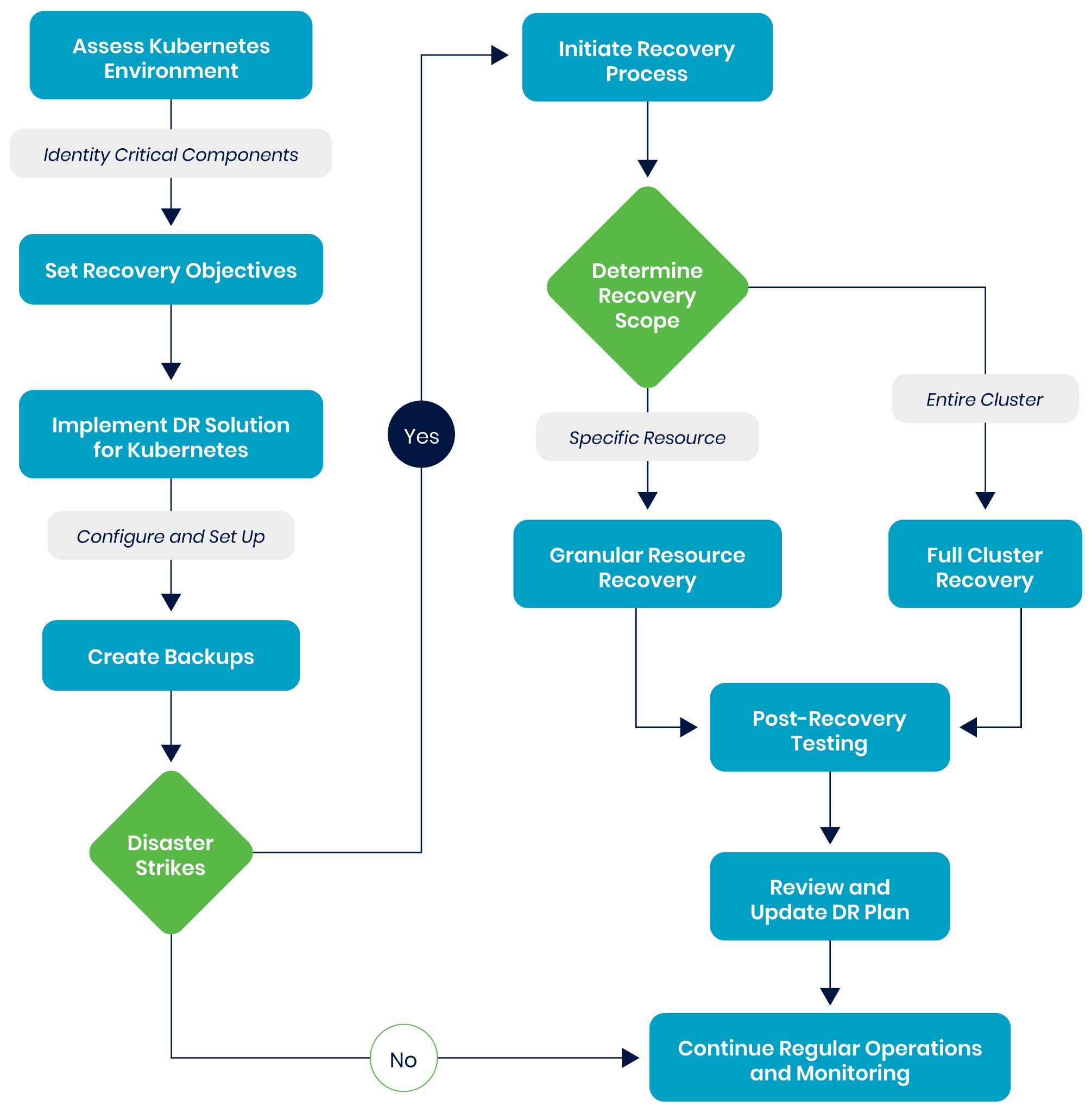
Laying out your Kubernetes disaster recovery plan
Developing a disaster recovery plan for Kubernetes can be complex. A well-structured plan should incorporate various DR methods, such as cold and warm standby, and allow the administrator to restore components based on criticality. This section will explore the technical steps in creating a production-grade DR plan.1. Assess and plan your backup requirements
- Identify critical components: Begin by auditing your Kubernetes environment. Pinpoint deployments, services, persistent volumes, and essential configurations. This identification process is crucial to understanding what needs to be included in the backups. Set recovery objectives: Define a clear recovery time objective (RTO) and recovery point objective (RPO). The RTO determines the maximum acceptable time your environment can be offline. The RPO refers to how much recent data you can afford to lose in case of disruption while resuming normal operations. One way to reduce RTO is to identify which components are the most critical to be restored first.
2. Implement granular recovery strategies
- Granular recovery options: Plan for scenarios requiring the recovery of specific elements of your cluster, like the ability to restore individual resources, such as particular pods, deployments, or persistent volumes, providing flexibility in handling various disaster scenarios.
- Restore testing: Regularly test granular restores to ensure that specific components can be recovered quickly and accurately without restoring entire applications or clusters. To simplify testing your restores, consider integration with automation and orchestration tools. We look into how to do this later in this article under Best Practices.
3. Set up multi-cloud and cross-cluster migrations
- Plan for warm-standby scenarios: Set up continuous data replication to a secondary, ready-to-go cluster if your strategy involves maintaining a warm-standby environment. This setup is handy for critical applications requiring high availability and minimal downtime.
- Replication configuration: Fine-tune the replication settings. Decide on the replication frequency, which will balance how current the data needs to be and the resources available for replication processes. Ensure the network bandwidth and storage resources are adequate for the replication load.
4. Regularly test and validate backup and recovery processes
- Conduct DR drills: Periodically simulate disaster scenarios to test the efficacy of backup integrity and recovery processes. This includes practicing the restoration of backups in a test environment to validate the recovery time against your RTO.
- Monitor and adjust: Utilize monitoring tools to track the performance of your backups. Adjust your DR strategies based on these insights and any changes in your Kubernetes environment or business requirements. A widely used and recommended way to monitor these metrics is through the Prometheus exporter and integration with Grafana. You can learn more about this through reading on how Trilio does observability with Prometheus and Grafana.
5. Document your DR plan
- Maintain clear documentation: Keep a comprehensive record of your DR strategy. This documentation should include detailed procedures for initiating backups, steps for recovery, and how to handle different disaster scenarios.
- Update as necessary: Regularly review and revise your documentation to stay current with your operational environment and DR strategies. This includes updating it for changes in your Kubernetes setup, configurations, or backup storage targets.
Best practices for Kubernetes disaster recovery
Here are a few best practices you should consider when developing a robust disaster recovery strategy for Kubernetes. 