Summary of key concepts related to Kubernetes backup tools
| What are the benefits of implementing Kubernetes backups? | Backups are a critical requirement of any production Kubernetes cluster. They enable disaster recovery, malware protection, and improved migration capabilities. |
| How do Kubernetes backups help with disaster recovery? | Backing up Kubernetes clusters enables administrators to quickly restore a cluster’s state as part of disaster recovery. Backups can include data like Kubernetes object schemas, persistent volumes, secrets, services, and other data required to get a cluster back online. |
| How can backups help with migrating between Kubernetes clusters? | Migrating data between clusters is challenging, but backup tools enable smoother migration by performing the heavy lifting of data transfer and validation. |
| How can backups protect against malware? | Infected and compromised workloads in a cluster can be mitigated by restoring data from backups with a clean, reliable copy of the data. |
| How can Kubernetes administrators develop an effective backup strategy? | Administrators should carefully gather requirements from their organization, check compliance rules, determine data sensitivity, build documentation and training, and validate backups regularly. |
| What are the best security practices when implementing Kubernetes backups? | Secure backup data with encryption, immutability, and restricted access controls. Protecting backup data is as important as securing any other data in a Kubernetes cluster. |
Benefits of Kubernetes backup tools
Backup tools can offer Kubernetes administrators many beneficial features to improve a cluster’s operational readiness and recovery capabilities. Many of these features are necessary for any production-critical environment, and administrators should understand why these features are valuable, so they can evaluate potential backup tools correctly.Disaster recovery
The primary benefit of Kubernetes backup tools is their ability to provide quick and reliable recovery options in the event of data loss. This feature is crucial for minimizing downtime and mitigating the impact of data breaches or system failures. Advanced tools offer data recovery and the restoration of Kubernetes workloads, ensuring your environment can be brought back online with minimal disruption. Recovery time objectives (RTOs) and recovery point objectives (RPOs) are commonly used to measure how quickly disaster recovery can be completed following an outage and how much data loss will occur. Maintaining control over the RTO and RPO measurements requires an adequate backup tool capable of quickly recovering a cluster after an outage.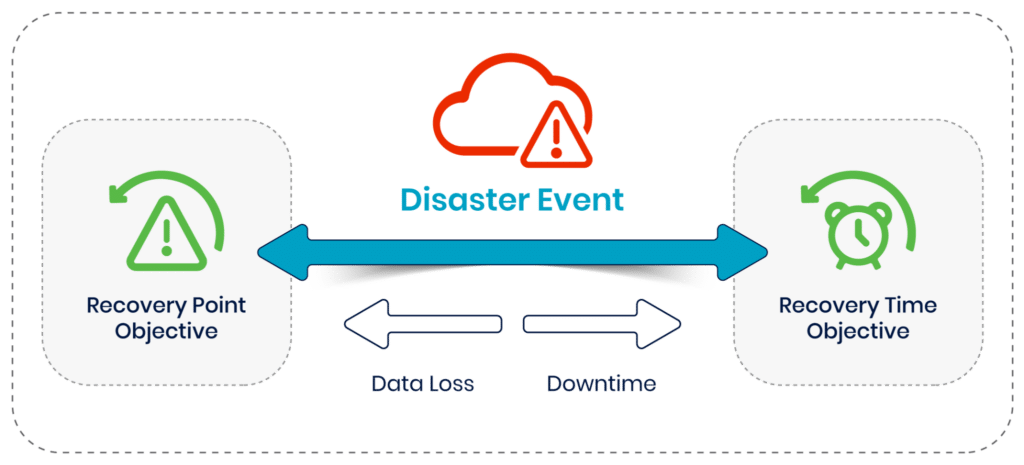
Once a disaster event occurs, the impact will be visible in terms of both data loss and downtime. RPO and RTO objectives measure how well the impact can be confined following a disaster.
Data protection
Implementing a backup strategy enables administrators to protect their data from accidental deletion, unwanted modifications, and compromised access. The backup copies must be protected to ensure that they are reliable and usable. Backup data protection features that Kubernetes administrators should expect from a backup tool include:- Immutability: To avoid unwanted deletion or modification of backups, they should be immutable, which means that the backup data cannot be deleted from the underlying storage location. This may be implemented by leveraging the storage location’s native functionality; for example, a backup tool that integrates with AWS S3 could leverage S3’s Object Lock feature, which blocks object deletion and modifications. Being immutable automatically improves the safety of the valuable backup data by adding a layer of protection.
- Role-based access control (RBAC): Backup data may be sensitive, and administrators will typically want to implement controls to manage access to creating and reading it. Implementing a backup tool that allows fine-grained RBAC configuration will enable administrators to implement use cases like ensuring that a user or team can only create and access backups created by them or that read-only users can view but not modify backup data. The ability to lock down access to backup data is crucial for limiting security breaches and accidental data changes.
- Retention policies: As part of developing a backup process, administrators should decide how many backups to retain and how frequently to create backups. For example, administrators may make backups daily and keep seven daily backups. The backup tool is expected to perform the backup automatically on the defined schedule and clean up excess backups. An organization may wish to extend this use case by stating that on top of retaining the latest seven daily backups, they also want to retain five weekly and seven monthly backups and one yearly backup. A tool providing these capabilities can offer advanced use cases with customizable retention options.
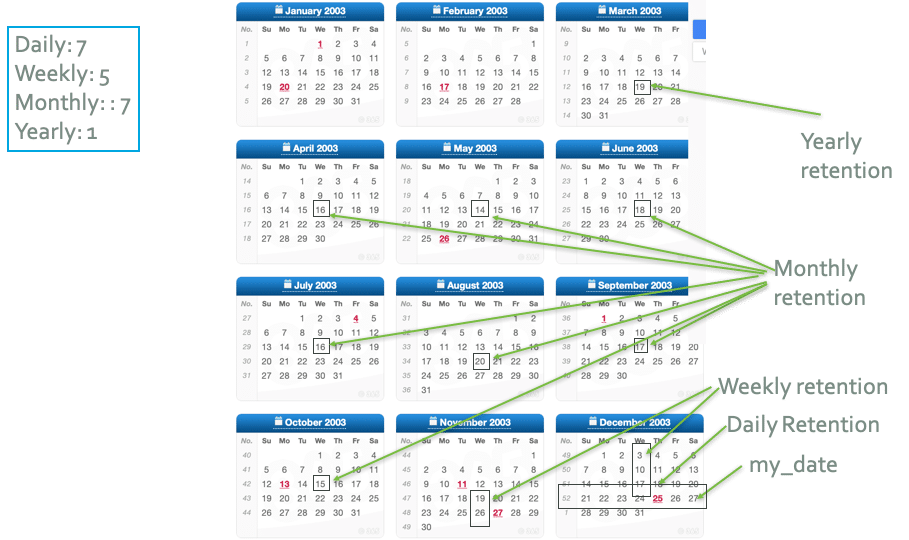
A backup retention policy for retaining daily, weekly, monthly, and yearly backup copies. A common setup is to retain many recent backups containing fresh data and a few older backups in case recent backups are compromised or if auditing archived data is necessary. Backup retention policies typically involve retaining a mixture of older and newer backup copies.
Multi-platform support
Many organizations use a multi-platform approach to hosting their environments, especially for Kubernetes users. Since Kubernetes abstracts many of a cloud’s vendor-specific infrastructure details, clusters are commonly run in multiple cloud providers or with a hybrid cloud/on-premises mixture. In these scenarios, access to Kubernetes backup tools that support multiple platforms allows a unified set of backup policies and strategies to be applied to all of the Kubernetes clusters.Malware protection
Backup tools with the right features can help protect against malware attacks in a variety of ways:- Immutable backups protect backup data against the threat of deletion or modification. Ransomware attacks typically involve moving or encrypting data maliciously, and maintaining access to an immutable copy of data protects against this attack.
- Encrypted backups based on user-managed encryption keys allow data to be secured and made unreadable by potential threats.
- Infected and compromised workloads in a cluster can be mitigated by restoring data from sanitized backups with a clean, reliable copy of the data.
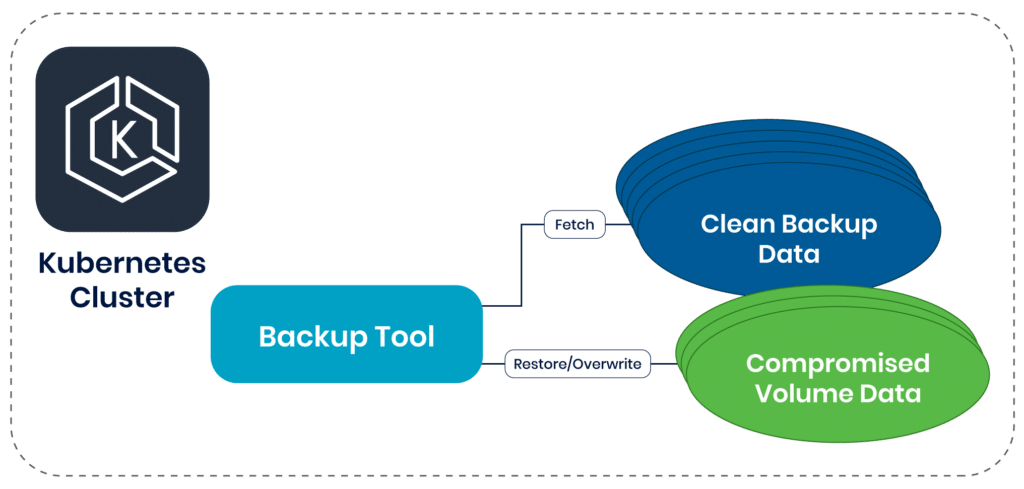
Compromised or damaged data can be restored easily when a backup tool can access clean backup data. Implementing a backup tool enables administrators to mitigate situations where data is deleted or modified maliciously.
A backup tool that implements all of the features above is Trilio. Trilio works as an operator in any Kubernetes cluster and leverages native functionality like CustomResourceDefinitions (CRDs) to implement the “backup” object type and Kubernetes RBAC to control access to Trilio backup resources. The tool is aware of Kubernetes constructs like persistent volumes, Helm charts, operators, etc., so it understands how to handle the backups of typical Kubernetes objects running in any cluster. Backups can be created with schedules and retention policies defined by the administrator as CustomResources, and Trilio will back up data to targets like S3 and FS. Trilio offers a Kubernetes-native experience to managing backups in any cluster, in the cloud or on-premises, and allows administrators to implement advanced backup capabilities quickly and easily.Developing a backup strategy
Creating a Kubernetes backup strategy involves decisions beyond just selecting the right tool. It also involves gathering requirements and understanding your organization’s needs to ensure that appropriate technical and process-related decisions can be made. This requires administrators to understand their use case, gather requirements, ensure that their team’s documentation is up to date, and validate their approach to implementing backups.Assessing use case requirements
Begin by evaluating the specific needs of your Kubernetes environment. This involves understanding the types of workloads running on your clusters, their criticality to your business operations, and how they interact with other systems. For example, backing up stateful applications will involve different steps (like snapshotting the underlying persistent volumes) compared with simply backing up the Kubernetes manifests for stateless applications. Exploring the requirements for your backup strategy will help define what resources need to be backed up and how often, how many copies should be retained, what security measures should be implemented, etc. The better you understand your requirements, the more precisely you can configure your backup tool to serve your needs.Compliance and RTO/RPO objectives
Compliance with legal and regulatory standards is a common requirement in many organizations. Identify your organization’s compliance requirements, such as backup retention policies, RPO/RTO targets, and security constraints like mandatory encryption for sensitive data. Compliance requirements are typically strict and should be a key consideration when evaluating a backup strategy that serves the organization’s needs.Data sensitivity and backup types
Analyze the sensitivity and criticality of the data within your Kubernetes clusters. This analysis will determine whether to opt for full backups, which capture the entire state of a system at a point in time, or incremental backups, which only capture the changes since the last backup. Incremental backups are typically more efficient in terms of storage and bandwidth usage. Data sensitivity will also determine whether encrypted backups are appropriate, whether the storage target needs to be secured with features like immutability, and how strictly to lock down RBAC policies.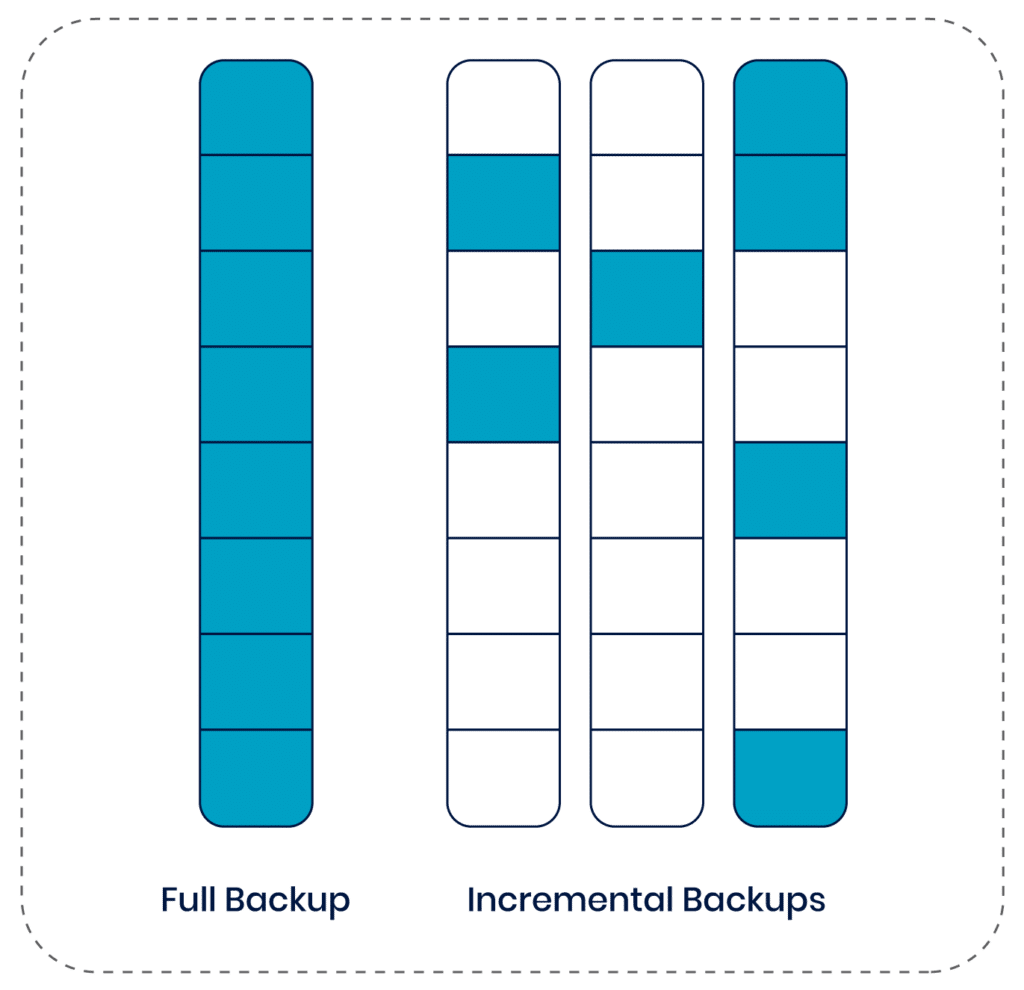
An efficient approach to continuously backing up a cluster is implementing incremental backups, which involve only snapshotting changed data instead of fully capturing all data during every backup. This allows administrators to reduce the space and bandwidth required when creating regular backups. Restoration is performed by merging each incremental backup with an initial full backup to reinstate the cluster’s data.
Documentation and training
Develop detailed documentation outlining your backup processes, tools, and procedures. This documentation should be accessible and understandable to your organization, especially for easy reference during disaster recovery scenarios. Documentation should include where backups are located, how to select which copies to restore, what the restoration process looks like, and how to validate that a restoration was completed successfully. Regular training sessions are also essential to ensure that your organization is equipped to execute restorations efficiently and effectively in case of a disaster.Regular testing
Regularly test your backups to ensure that they can be restored successfully and that your team understands the procedure well. This involves conducting restoration drills that mimic real-world disaster scenarios, like accidental deletion of a production workload or cluster infrastructure. Testing helps verify the integrity of your backups and the effectiveness of your restoration procedures. It also helps your team gain confidence in handling a real-world disaster recovery scenario and identify and rectify gaps or issues in your backup strategy.Implement observability
Observability is a key aspect of validating that backup tools are working correctly. Tools that integrate with Prometheus, like Trilio, can provide valuable metrics to give you insight into the status of backups in your Kubernetes clusters. Metrics related to tool health status, backup/restore progress status, storage utilization, and average backup/restore duration allow administrators to understand whether their backup tool is working and whether any metrics need attention. Access to observability data means that administrators can discover and troubleshoot problems quickly rather than discovering issues too late during disaster recovery situations.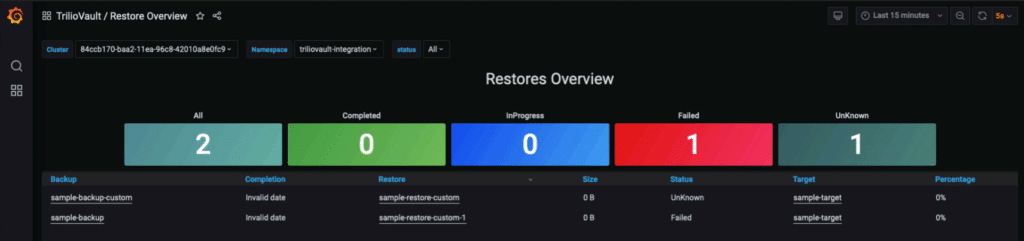
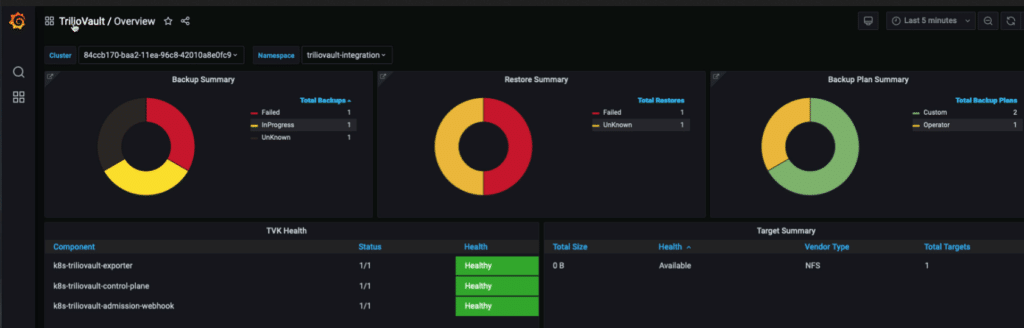
Examples of Trilio’s Prometheus metrics being displayed via Grafana dashboards. The metrics allow administrators to easily view the status of backups in their clusters.
Backup security best practices
There are several considerations related to securing Kubernetes backups to keep in mind. Compromised backup data can cause security incidents at the same scale as a compromised cluster due to the potentially sensitive nature of backup data, including customer information, secrets, application code, and more. Implementing security best practices will be essential for any production-ready backup strategy, including the following actions:- Maintain Strict RBAC: A backup tool offering RBAC features should be leveraged to ensure backups are protected from unauthorized access. Access to backup data should be locked down to required users only. Granular RBAC policies allow use cases like enabling each team to access only the backup data they created and using read-only policies to restrict write access to the backup target and modifications to backup configurations. Kubernetes RBAC (roles and bindings) can control access to backup tools like Trilio.
- Encrypt backups: Encrypting your backup data is always recommended for any use case since it is an easy feature to implement and provides a significant degree of security. This security measure may involve using formats like LUKS to encrypt all backup data, limiting the potential impact of a compromised storage target.
- Secure storage targets: The security of where backups are kept, such as S3, is critical for protecting unwanted access to backup data. Ensure that the storage target is secured with the storage target’s native features; for example, AWS S3 allows encryption at rest, bucket access policies, access logs, and object immutability. Leverage these features to ensure that the storage target is secured and all backup data is well protected.
- Implement monitoring and alerting: Enable alerting for when sensitive backup data is accessed or any suspicious backup-related activities occur, like changes to backup configuration and RBAC settings. This alerting will help administrators become aware of potentially compromised backup data or unwarranted changes to backup configurations.
