Elastic Kubernetes Service (EKS) clusters are the backbone of many Kubernetes deployments. However, managing these clusters can quickly become complex, particularly regarding disaster recovery, application mobility, and data protection. As your EKS infrastructure expands to accommodate diverse tools and skill sets, the need to safeguard against potential disasters, facilitate seamless application movement, and protect valuable data increases.
In this article, we break down EKS backup into five levels, starting with a simple example of configuring an EKS backup. Next, we dive into creating a solid EKS backup strategy and explore four common goals: disaster recovery, application mobility, data protection and ransomware protection with S3 Object Locking.
Summary of key EKS backup concepts
The table below summarizes the key EKS backup concepts this article explores.
| Concept | Description |
| Understanding AWS EKS backup | AWS backup typically represents a combination of five distinct levels: cluster-level backup, node-level backup, data volume backup, control-plane, and application-level backup. |
| Implementing AWS EKS backup | Implementing typical cluster-level EKS backup for disaster recovery includes handling persistent data, pod definitions, ConfigMaps, secrets, and other items. |
| Developing an EKS backup strategy | The right backup strategy depends on your specific goals, such as disaster recovery, application mobility, or data protection. These objectives determine which combination of backup levels to use. |
| Disaster recovery for EKS | EKS point-in-time backups and restores can be created and leveraged in case of outages at the primary site to restore an entire environment to a separate location, fulfilling disaster recovery requirements. |
| Application mobility with EKS backups | Application-aware backups, when implemented properly, provide a way to migrate applications between Kubernetes clusters and cloud providers by performing a point-in-time copy of the application. |
| Data protection on EKS | Using backup and recovery technology, point-in-time backups and restores can be created for cloud-native applications, protecting them from data corruption or malicious activity on production data. |
Understanding AWS EKS backup
To achieve comprehensive data protection and disaster recovery, you should be aware of five distinct levels of EKS backups: cluster-level backup, node-level backup, data volume backup, control-plane, and application-level backup. These options offer a spectrum of strategies to safeguard your EKS environment and ensure its in the face of unexpected challenges.
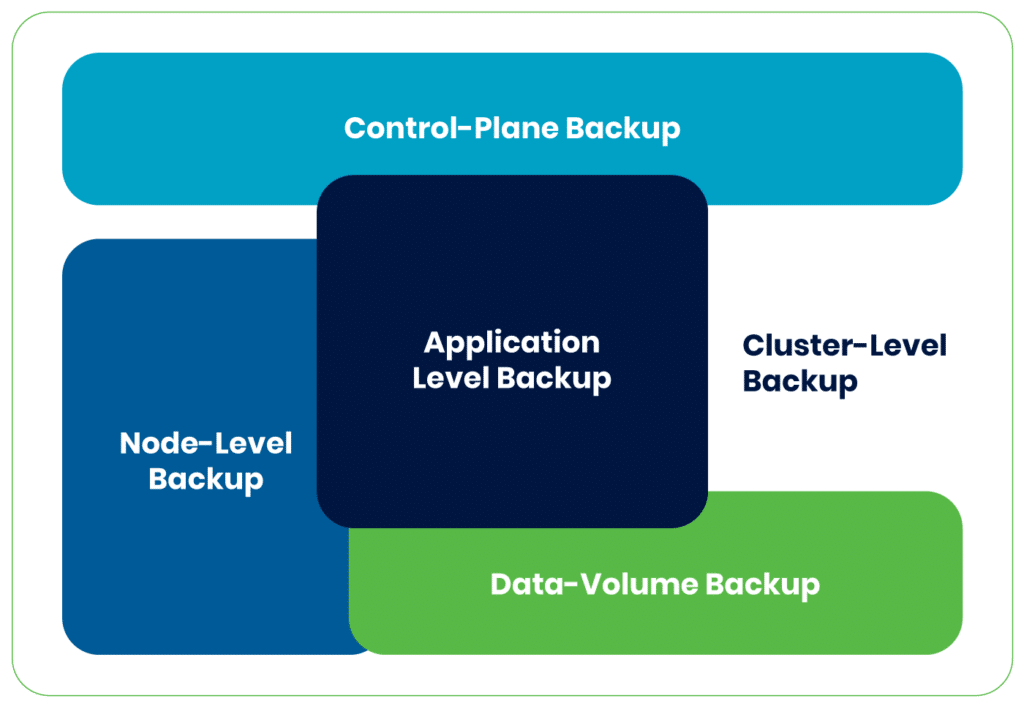
Diagram of EKS backup levels
The table below provides more details on these different types of backups.
Backup type | Description | Why it’s important |
Cluster-level backup | A full-cluster backup should encompass the entire Amazon Elastic Kubernetes Service (EKS) cluster, worker nodes, networking, and all applications and data running within the cluster. | It provides the most comprehensive backup, allowing you to recover the entire cluster in case of a catastrophic failure or replicate it in a different AWS region. |
Control plane backup | Control plane backup is a crucial part of an EKS backup strategy that focuses on capturing and preserving the configuration and state of the EKS control plane components, including the API server, etcd database, and authentication mechanisms. | Control plane backups are essential for disaster recovery, ensuring that you can restore the control plane’s configuration and state in case of failure or unexpected issues. |
Node-level backup | Node-level backups are a subset of full-cluster backups, focusing on capturing the state and data specific to individual worker nodes within the EKS cluster. | These backups allow you to restore specific nodes or troubleshoot node-specific issues without affecting the entire cluster. |
Data volume backup | These are another subset of full-cluster backups, concentrating on capturing the data stored in persistent volumes associated with pods running in the EKS cluster. | They protect against data loss for stateful applications and allow you to restore application-specific data without restoring the entire cluster. |
Application-level backup | Application-level backups are a further subset, honing in on the state and data specific to the applications running within the EKS cluster. | These backups encompass application configurations, databases, and any other application-specific data necessary for the application’s functionality and recovery. |
In summary, while full-cluster backup should encompass backup of all the applications within EKS cluster, control plane, node-level, data volume, and application-level backups are more granular, focusing on specific components or data within the cluster. Organizations should use a combination of these backup strategies to ensure data protection and recovery at various levels of granularity, depending on their specific requirements and the application architecture.
Although there are various methods for implementing application-level and data volume backups, there is currently no single comprehensive cluster-level backup solution offered by AWS.
Implementing AWS EKS backup
Let’s review a simple example of setting up a backup for EKS.
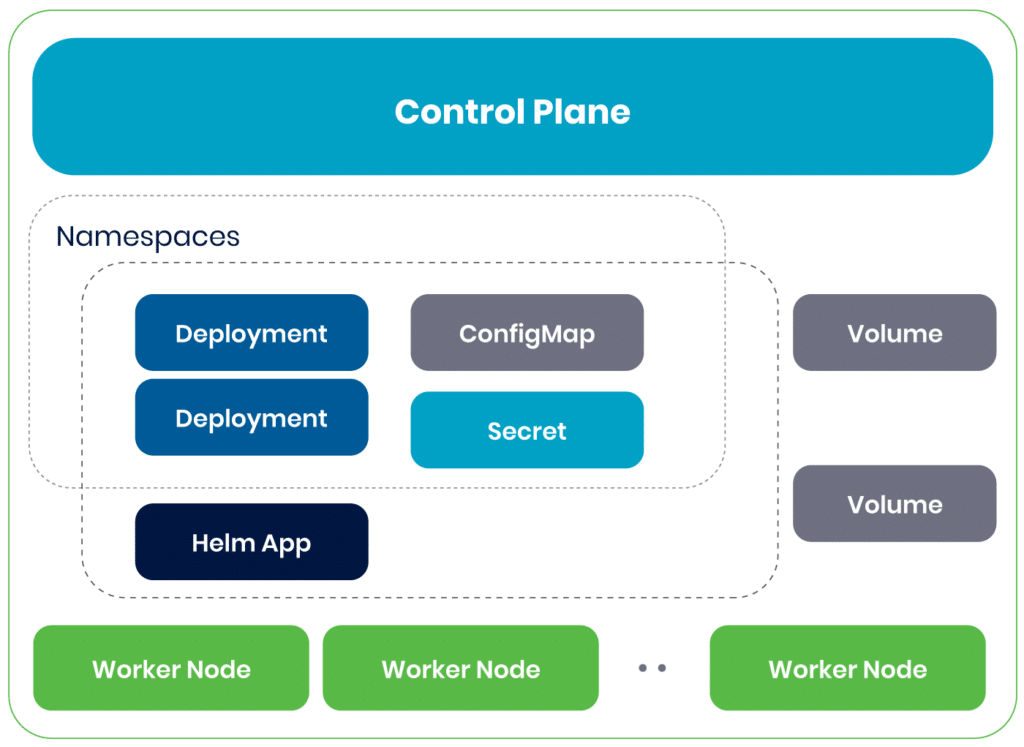
Diagram illustrating the components to be backed up in a cluster-level scenario.
Imagine a Kubernetes administrator tasked with setting up a system for backing up Kubernetes for recovery in the event of a disaster. For this scenario, it will most likely be a cluster-level backup. To achieve this, an engineer might follow a flow similar to the one described below.
Note that while these examples provide clarity on individual resource backup, the commands need to be reiterated multiple times to account for the various resources present in the cluster. As the number of resources grows, the complexity of the workflow increases proportionally. This repetition can lead to a convoluted and time-consuming backup process, making it challenging to manage and ensure that all essential components are adequately protected. To streamline and simplify the backup process, it’s essential to consider automated solutions or scripting that can efficiently handle backups for multiple resources, ensuring comprehensive data protection without the burden of manual repetition.
Step 1: Back up the control plane configuration
- API server and control plane components: You can use a tool like etcdctl to back up the etcd database, which stores the cluster’s configuration data. Here’s a sample command to create a snapshot of the etcd database:
etcdctl snapshot save /path/to/snapshot.db
- Authentication mechanisms: Back up authentication mechanisms like certificates and tokens by securely storing copies of these files in a backup directory.
- OIDC configuration: If you’re using OpenID Connect (OIDC) for authentication, the OIDC configuration, including issuer URL and client IDs, should be backed up. This information is crucial for establishing trust between your EKS cluster and OIDC identity providers.
Here are the commands to back up the OIDC configuration in an EKS cluster:
# Get the OIDC issuer URL for your EKS cluster eks_cluster_name="" region="" oidc_issuer_url=$(aws eks describe-cluster --name $eks_cluster_name --query "cluster.identity.oidc.issuer" --region $region --output json | jq -r '.') # Save the OIDC issuer URL to a backup file echo $oidc_issuer_url > eks_oidc_issuer_url.txt # Store the backup file securely in your backup repository # Ensure that the backup file is adequately protected, as it contains sensitive configuration information.
- IAM role mapping: Certain authentication-related configurations specific to your EKS cluster—such as the enabled identity providers, role mappings, and authentication token settings—should be included in your backup strategy. These settings play a significant role in determining how users and services authenticate and access the cluster.
Here are the commands for backing up IAM roles in an EKS cluster:
# List all IAM roles associated with your EKS cluster
aws iam list-roles --query "Roles[?starts_with(RoleName, 'eksctl-')]" --output json > eks_iam_roles.json
# Backup IAM policies attached to these roles
for role in $(cat eks_iam_roles.json | jq -r '.[].RoleName'); do
policy_name=$(aws iam list-attached-role-policies --role-name $role --query "AttachedPolicies[0].PolicyName" --output json | jq -r '.')
aws iam get-role-policy --role-name $role --policy-name $policy_name --output json > eks_${role}_policy.json
done
# Store the IAM role policies and configurations securely in your backup repository
# Make sure to follow proper security practices for storing these sensitive files. AWS EKS backup with Trilio
Trilio for Kubernetes is a data protection and backup solution specifically designed for Kubernetes environments. It provides backup and recovery capabilities tailored for these dynamic, container-based infrastructures.
Trilio gives you the power and flexibility to back up all the applications deployed in your EKS cluster or select a specific namespace, label, Helm chart, or operator as the scope for your backup operations. All of that functionality is encapsulated within a convenient interface utilizing Kubernetes custom resource definitions (CRDs) specified in YAML.
Let’s examine how much simpler this configuration can be with automated solutions such as Trilio. After the initial setup, a namespace-scoped backup can be configured using the following commands with the example namespace scope BackupPlan.
First, let’s create ns-backupplan.yaml. Save the following into a text file using your editor of choice.
apiVersion: triliovault.trilio.io/v1 kind: BackupPlan metadata: name: ns-backupplan spec: backupConfig: target: namespace: default name: demo-s3-target
Now, we’ll apply it with this command:
kubectl apply -f ns-backupplan.yaml
Next, we create sample-schedule.yaml:
kind: "Policy"
apiVersion: "triliovault.trilio.io/v1"
metadata:
name: "sample-schedule"
spec:
type: "Schedule"
scheduleConfig:
schedule:
- "0 0 * * *"
- "0 */1 * * *"
- "0 0 * * 0"
- "0 0 1 * *"
- "0 0 1 1 *"Next, we apply the file:
kubectl apply -f sample-schedule.yaml
Now we create sample-retention.yaml:
apiVersion: triliovault.trilio.io/v1
kind: Policy
metadata:
name: sample-retention
spec:
type: Retention
default: false
retentionConfig:
latest: 2
weekly: 1
dayOfWeek: Wednesday
monthly: 1
dateOfMonth: 15
monthOfYear: March
yearly: 1And then apply it:
kubectl apply -f sample-retention.yaml
Now we create sample-backup.yaml:
apiVersion: triliovault.trilio.io/v1
kind: BackupPlan
metadata:
annotations:
finalizers:
- backupplan-delete-finalizer
generation: 2
name: eks-backupplan
namespace: eks-backup
spec:
backupConfig:
schedulePolicy:
fullBackupCron:
schedule: ""
incrementalCron:
schedule: ""
target:
apiVersion: triliovault.trilio.io/v1
kind: Target
name: trilio-target-eks
namespace: eks-backup
backupPlanComponents: {}
retainHelmApps: falseAnd apply this file as well:
kubectl apply -f sample-backup.yaml
This configuration would encapsulate a full namespace backup, which can be restored using the restore procedure.
Once the sample-backup.yaml has been applied, the following screenshot is what the backup plan looks like in the UI.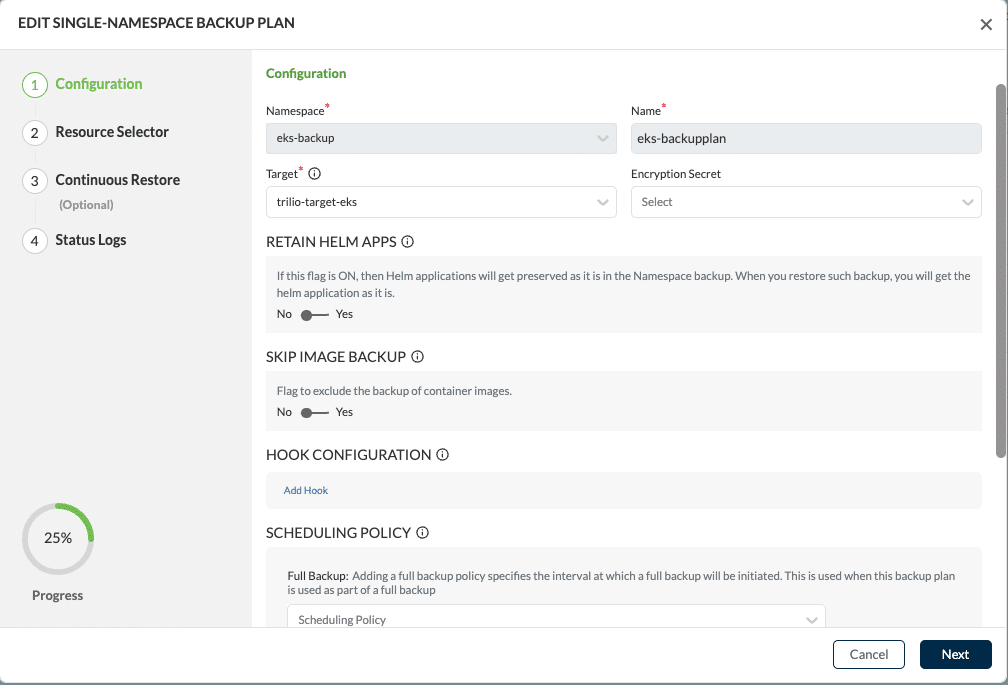
Developing an EKS backup strategy
The ideal choice of EKS backup strategy depends on factors such as the criticality of applications, cost considerations, and recovery time objectives (RTOs). Organizations may opt for a combination of these strategies to strike the right balance between data protection, cost-effectiveness, and operational efficiency.
When crafting an EKS backup strategy, having specific goals in mind is important. We’ll discuss three key objectives: disaster recovery, application mobility, and data protection. These objectives guide how to design backup plans and procedures in EKS. Each goal serves a distinct purpose, helping ensure that the EKS setup is resilient, flexible, and secure, addressing different scenarios and needs for containerized applications.
Typical backup strategy objectives
Disaster recovery (DR)
Disaster recovery is all about preparing for worst-case scenarios such as hardware failures, data corruption, or even regional outages. In this context, a robust EKS backup strategy ensures that we can quickly restore our EKS cluster to a known good state.
Backup levels for disaster recovery: Full-cluster backups and control plane backups are crucial. Full-cluster backups capture everything, while control plane backups safeguard the control plane components. Node-level backups provide node-specific recovery options in case of hardware issues, and data volume backups protect critical application data.
Application mobility
Application mobility focuses on the seamless movement of applications across different environments or AWS regions. This goal often comes into play when you need to scale or migrate applications without disruption.
Backup levels for application mobility: Full-cluster and application-level backups play key roles here. Full-cluster backups ensure that the entire cluster can be moved, while application-level backups help package and move specific applications with their configurations and data.
Data protection
Data protection focuses on safeguarding your application data, ensuring its availability, integrity, and compliance with regulatory requirements. It’s crucial for maintaining the trust and continuity of your services.
Backup levels for data protection: Data volume backups are of paramount importance and focus on preserving your application’s data, ensuring that you can recover it if it is lost or corrupted. Application-level backups can also be used to protect application-specific configurations and data.
Disaster recovery for EKS
The ability to recover from disasters is necessary to ensure uninterrupted business operations. Organizations require a well-defined DR strategy when managing one or multiple applications. Such strategies can be stored in Git as a source of truth and managed using the GitOps workflow, ensuring consistency and reliability.
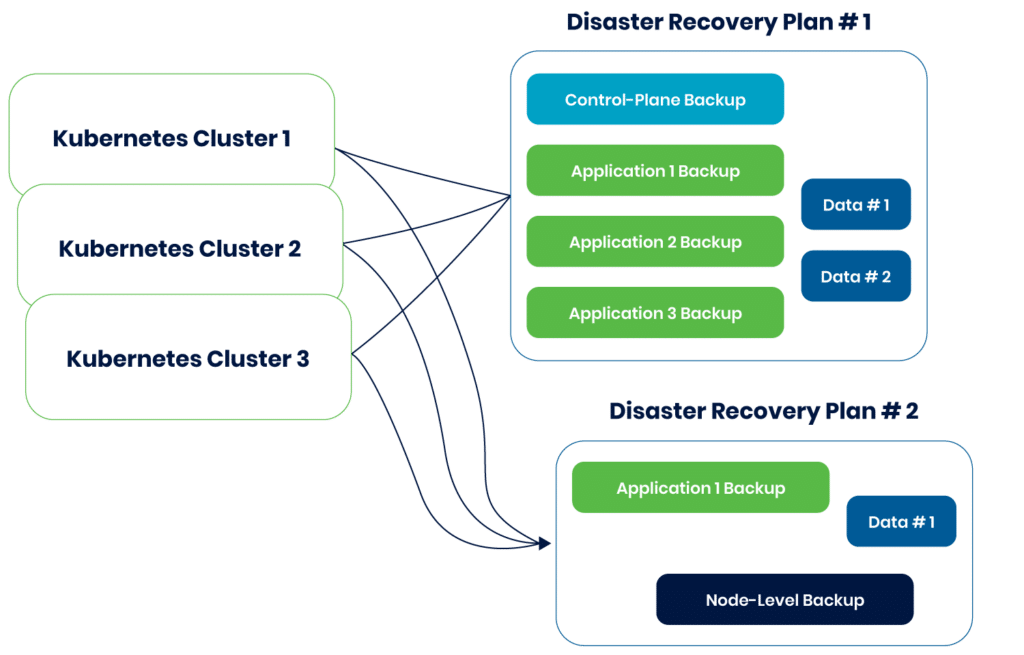
Visualized examples of disaster recovery plans
Challenges with critical applications
Configuring disaster recovery for critical applications presents one of the most significant challenges for Kubernetes administrators. Some key challenges include:
- Managing complex application dependencies: Ensuring the accurate recovery of intricate dependencies is crucial to prevent disruptions in critical application functionality.
- Configuration and secrets management: Proper disaster recovery requires the precise restoration of configurations and secure handling of secrets, such as API keys and passwords.
Turn-Key Disaster Recovery Plans
To address these challenges, it is ideal to implement a simple turn-key solution that can back up critical applications along with their dependencies and let you restore multiple applications or namespaces to a different cluster in parallel.
The Trilio DRPlan feature lets users restore multiple applications and namespaces efficiently within a single workflow, facilitating the seamless resumption of business operations. The process is made user-friendly through a management console located within the destination cluster.
Through this feature, users can create and execute various DRPlans tailored to the criticality of applications. These plans can source data from multiple targets or backup locations, ensuring flexibility in disaster recovery. Notably, the DRPlan is stored within the destination cluster, enabling execution even when the source cluster is inaccessible.
Application mobility with EKS backups
In Kubernetes deployments, we use three important methods to manage applications:
- Label-based
- Helm-based
- Operator-based
Each method relies on a distinct Kubernetes working mechanism and offers specific advantages. Trilio’s application-aware backup system leverages those standard capabilities and implements an intelligent and holistic application mobility solution. Let’s review that in detail:
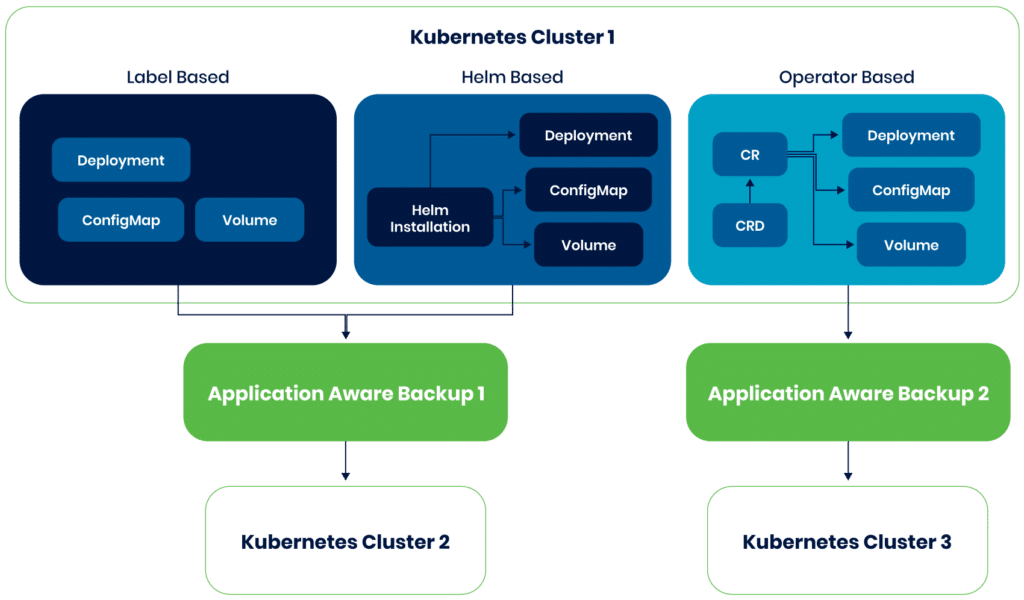
Visualized examples of application mobility
Label-based applications
For label-based applications, Trilio relies on user-defined labels associated with application resources. During the backup process, the system lists all Kubernetes resources matching the specified labels and identifies resource dependencies, ensuring comprehensive backups. For example, if a deployment bears the specified label, the system ensures that associated resources like service accounts are also included in the backup to maintain consistency.
Helm-based applications
In the case of Helm-based applications, the backup strategy should operate on the Helm release name as input. Moreover, if the Helm release includes dependent Helm subcharts, the backup strategy should take care of them as well.
In such cases, Trilio’s application mobility system intelligently decodes the Helm release secret within the same namespace to identify the associated resources. After that, it extends the backup to encompass resources from these subcharts. During restoration, the application is reconstructed as a Helm chart, offering flexibility and treating the entire application as a new Helm release.
Operator-based applications
Operator-based applications typically consist of custom resource definitions (CRDs) and controllers. Trilio facilitates backup by considering operator resources, custom resources, and application resources as input. Within operator resources, it can identify resources based on user-defined labels or Helm release names, depending on the operator’s installation method. For custom resources, Trilio requires the CR name and its associated CRD, which includes the GroupVersionKind (GVK).
To identify application resources, the system relies on the reconciliation process initiated by the operator. It automatically detects these resources using owner references from the CR. In cases where operators do not establish owner references, the system uses the provided labels to identify the associated resources.
Data protection on EKS
Robust data protection is essential to safeguard cloud-native applications from potential data corruption or malicious activities that can jeopardize production data. Leveraging advanced backup and recovery technology, like that Trilio offers, is a powerful solution to address these critical concerns.
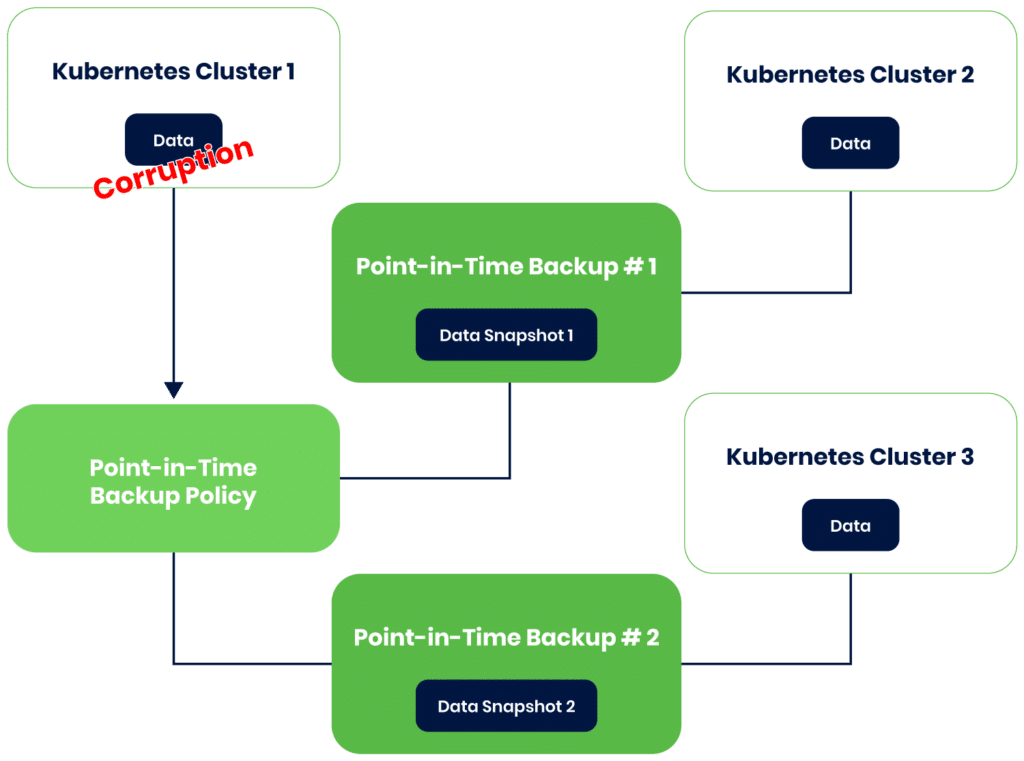
Visualized examples of data protection on EKS
Point-in-time backups for data protection
One of the fundamental pillars of data protection within EKS is the concept of point-in-time backups. These backups capture the state of your cloud-native applications at specific moments in time, allowing you to revert to a known, healthy state in case of data corruption, accidental deletions, or malicious attacks like ransomware. Creating point-in-time backups establishes a secure and restorable copy of your applications and their data, reducing the risk of prolonged downtime and data loss.
Restoring data integrity
Ensuring data accuracy is a critical aspect of EKS backup. Highly accurate backup data guarantees that it faithfully represents the state of the original resources at the time of backup. Inaccuracies in backup data can lead to data corruption or loss during the restoration process, undermining the reliability of disaster recovery efforts. Meticulous attention to data accuracy is essential for maintaining the integrity of EKS backups.
Data consistency is another vital dimension of EKS backup. Consistency ensures that backup data is coherent and free from discrepancies, preventing issues that may arise from incomplete or mismatched data during recovery. Maintaining data consistency throughout the backup lifecycle is imperative to minimize disruptions and maintain the effectiveness of data protection strategies for EKS clusters.
Proactive data protection measures
The prevalence of ransomware attacks highlights the need for proactive data protection measures. Organizations must be prepared to defend against such threats by implementing a robust backup and recovery strategy. Regularly scheduled point-in-time backups coupled with secure storage practices provide a proactive defense against data loss and ensure that critical applications and their data are shielded from potential threats.
Here are a few examples of such measures:
- Enabling encryption: Implementing encryption for EKS backups adds an additional layer of security, safeguarding data from unauthorized access or breaches. Encryption measures, such as AWS Key Management Service (KMS), help protect backup data both in transit and at rest.
- Access controls: Robust access controls and policies should be in place to restrict unauthorized access to EKS backup data. By defining granular permissions and role-based access, organizations can ensure that only authorized personnel can manage and restore backups.
- S3 data lock features: including S3 Object Lock, offer an additional safeguard against accidental or intentional data deletions, ensuring data integrity over time. It’s worth noting that Trilio can seamlessly interface with S3 Object Lock, allowing for smooth integration and proper functioning with locked objects. This capability enhances data protection efforts, providing organizations with added assurance in their backup and recovery processes.
