


In a Kubernetes setting, ensuring the integrity and accessibility of your data is crucial and database backups play a role in achieving this. With Kubernetes clusters handling amounts of data and offering scalable infrastructures it becomes essential to implement a reliable backup strategy to protect your valuable information.
MySQL, an used database system within Kubernetes clusters offers advantages that make it an ideal choice. Its robust architecture and excellent scalability features provide an experience for managing databases in a Kubernetes environment.
Regardless of the database system you opt for, having data backups is imperative. Backups ensure that in the event of hardware failures, human errors or unforeseen circumstances your data remains protected and can be swiftly restored while preserving its integrity and accessibility.
Within a Kubernetes environment MySQL Cluster plays a role in data management. It facilitates sharding by distributing data across nodes to ensure high availability and fault tolerance. The cluster’s architecture enhances performance while maintaining data consistency during network or hardware issues.
Furthermore MySQLs replication feature allows for redundant copies of your data to be created, further improving both data availability and fault tolerance.
Replication is a process that allows data to be copied and synchronized across MySQL instances. It helps distribute the workload and creates a system that can be used if the primary database fails.
Understanding Kubernetes
Kubernetes is a platform for container orchestration. It helps automate the deployment, scaling and management of applications that are containerized. It offers a framework to manage and run applications across a cluster of machines.
- Pods: In Kubernetes pods are the most basic units. They serve as an environment for running one or more containers. Each pod has its IP address, which makes communication and resource sharing easy.
- Nodes: Nodes are machines within a Kubernetes cluster that can run pods simultaneously. These nodes can be virtual machines. Kubernetes takes care of scheduling pods onto nodes ensuring workload balance and high availability.
- Deployments: Deployments define the desired state of a group of pods and manage their lifecycle. They ensure that the desired number of pod replicas is maintained while handling tasks, like scaling, rolling updates and rollbacks.
Using Kubernetes to manage applications and databases brings advantages. It enables utilization of resources since multiple pods can be deployed on one node. Additionally Kubernetes provides built in load balancing and automatic scaling capabilities to ensure availability and efficient handling of increased traffic.
What is a MySQL Database
MySQL is an open-source relational database (DB) management system developed by Oracle. A relational database operates by organizing data into tables that can be connected based on the data they have in common. These relations are used to structure the data. MySQL is used by many database-driven web applications, including Drupal, Joomla, phpBB, and WordPress. MySQL is also used by many popular websites, such as Facebook, Flickr, MediaWiki, Twitter, and YouTube.
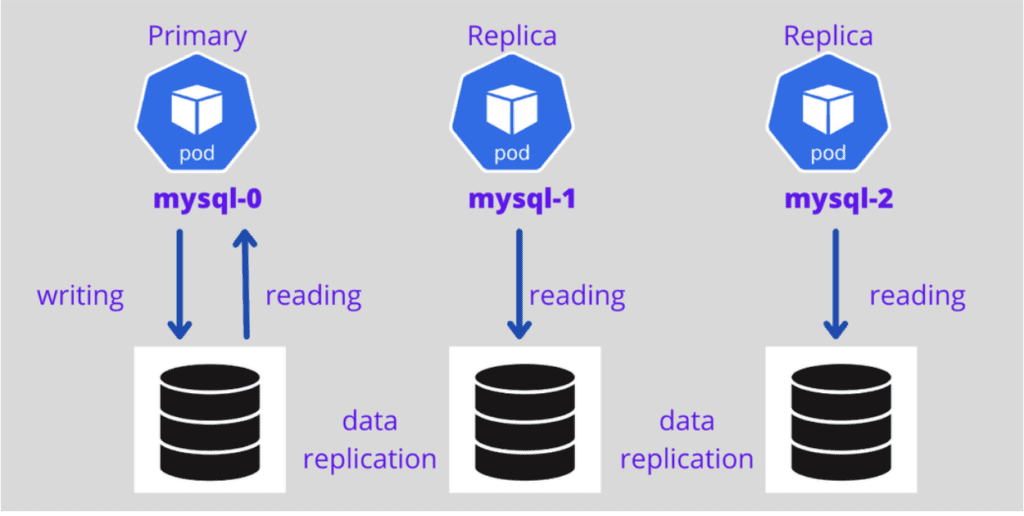
You can read more about it and StatefulSets in this link StatefulSets Examples and Best Practices
Disaster Recovery and Maintaining Availability, in Kubernetes MySQL
A. Strategies for Handling Disasters
Having a plan for disaster recovery is crucial when it comes to Kubernetes MySQL deployments. It ensures that your business can keep running and prevents any loss of data. In case of events like hardware failure or natural disasters having a defined recovery strategy becomes even more important.
One key element of disaster recovery is regularly backing up your MySQL data. By doing so you can restore it to a state if any failures or data corruption occur. Kubernetes MySQL backup solutions offer options for creating and managing backups, including backups and incremental backups.
Another essential aspect of disaster recovery is data replication. By replicating your MySQL data across nodes or clusters you can achieve near real time replication minimizing the risk of data loss and ensuring redundancy. In case of a failure you can quickly switch to a replica. Continue operations without downtime.
B. Considering Availability
Maintaining availability for MySQL databases within Kubernetes clusters is crucial to ensure uninterrupted access to your data and prevent any disruptions to your applications. High availability refers to the ability of your system to keep functioning when faced with hardware or software failures.
To ensure service there are methods available, for achieving high availability. Kubernetes offers features like StatefulSets and ReplicationControllers that facilitate the creation of replicas and distribution of workload across MySQL pods. This means that even if one pod fails the others can step in and handle requests minimizing the impact of failures on your applications.
Data replication is also crucial for achieving availability. By replicating your data across nodes or clusters you can distribute the workload. Reduce the risk of single points of failure. In case one node or cluster fails the other replicas can seamlessly take over and continue serving requests.
C. Business continuity
In addition to disaster recovery and high availability it’s important to consider business continuity when deploying Kubernetes with MySQL. Business continuity refers to maintaining business operations and services during and after events. By implementing strategies for disaster recovery and high availability you can ensure that your business continues functioning in challenging circumstances.
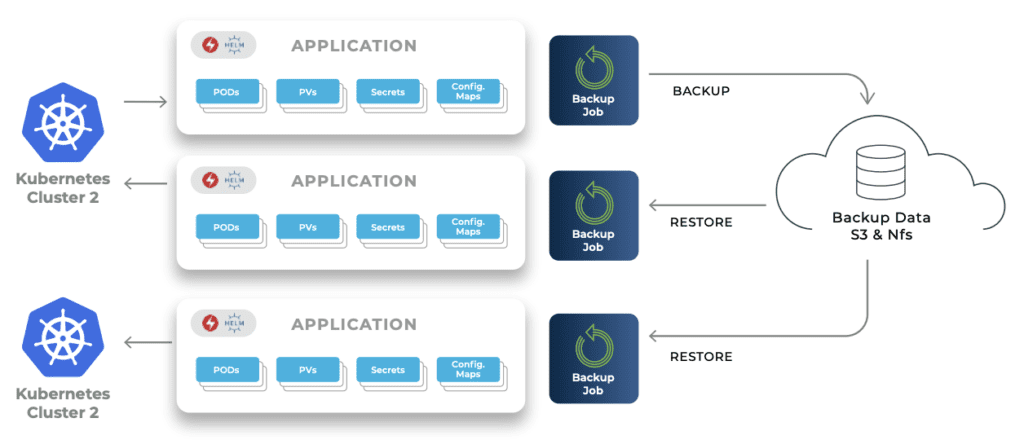
The significance of backing up data in a Kubernetes MySQL
It plays a role in managing the deployment by ensuring protection against hardware failures, mitigating the risks associated with data corruption and facilitating recovery from deletions. Reliable database backups are indispensable for maintaining access to information.
In a Kubernetes MySQL environment one potential risk is hardware failures even when robust infrastructure is in place. These unexpected failures can result in data loss unless appropriate backup measures are implemented. Regularly backing up data ensures that the recent information can be easily restored in case of any hardware mishaps.
Data corruption poses another challenge for organizations utilizing Kubernetes MySQL. Corruption may occur due to factors like software glitches, power outages or human errors. Without backups such instances of corruption can lead to periods of system downtime and potential loss of critical data. Regular database backups provide an avenue to restore the data to its state and minimize the impact caused by corruption.
Accidental deletions are not uncommon, within IT infrastructures, including Kubernetes MySQL deployments. It’s easy for individuals to unintentionally delete databases or tables resulting in loss of vital information.
Having backups in place enables resolution of deletions by restoring the data from a previous backup ensuring minimal disruption to business operations.
Effective database backups are crucial, in managing these risks and ensuring data availability. By implementing a backup strategy businesses can reduce the impact of hardware failures, prevent data loss caused by corruption and swiftly recover from inadvertent deletions. With dependable backups organizations can restore data to its reliable state allowing uninterrupted business operations even during unforeseen events.
Step-by-Step Procedure for Backup and Restore of MySQL DB
- Prerequisites — Install Trilio for Kubernetes and configure the following these steps:
- Install Test CSI Driver — Leverage the test host path CSI driver — if your environment does not support the driver with Snapshot capability.
- Software Access and Installation — Access the Trilio for Kubernetes software and install it based on the specific directions for your environment.
- License — Leverage the Free Trial or Free Basic Edition license (if not using Enterprise Edition) by following the instructions on the licensing page.
- Create a target where backups will be stored
-
- An Amazon S3 target example is provided below:
apiVersion: triliovault.trilio.io/v1
kind: Target
metadata:
name: demo-s3-target
spec:
type: ObjectStore
vendor: AWS
objectStoreCredentials:
url: "https://s3.amazonaws.com"
accessKey: "AaBbCcDdEeFf"
secretKey: "BogusKeyEntry"
bucketName: "S3_Bucket_US_East"
region: "us-east-1"
thresholdCapacity: 100Gi
$ kubectl create -f tvk-backup-target.yaml
- Create MySQL DB deployment using a Helm chart
Use the MySQL helm chart to deploy the application on the default namespace.
$ helm repo add stable https://charts.helm.sh/stable
$ helm repo update
$ helm install mysql-qa --set mysqlRootPassword=triliopass stable/mysql
- Insert test data
Port-forward the mysql-qa service to listen on the 3306 port.
Run command:
$ kubectl port-forward --address 0.0.0.0 svc/mysql-qa 3306:3306 &>/dev/null
Run a python script to insert some test data into the mysql database. Create a python file mysql_helm_insert_data.py.
Install mysql client python library if not present
# For python2 env
# pip install mysql-connector
# For python3 env
# pip3 install mysql-connector
#!/usr/bin/python
import mysql.connector
mysql_host= "127.0.0.1"
mysql_user="root"
mysql_password="triliopass"
mydb = mysql.connector.connect(
host=mysql_host,
user=mysql_user,
passwd=mysql_password
)
mycursor = mydb.cursor()
## Create Database: 'trilio_qa'
mycursor.execute("CREATE DATABASE IF NOT EXISTS trilio_qa")
# Close the database connection
if(mydb.is_connected()):
mycursor.close()
mydb.close()
print("connection is closed")
## Create new connection object with database - 'trilio_qa'
mydb = mysql.connector.connect(
host=mysql_host,
user=mysql_user,
passwd=mysql_password,
database="trilio_qa"
)
mycursor = mydb.cursor()
## Create table: 'users'
mycursor.execute("CREATE TABLE IF NOT EXISTS users (firstname VARCHAR(255), lastname VARCHAR(255))")
sql = "INSERT INTO users (firstname, lastname) VALUES (%s, %s)"
val = [
( 'Peter', 'Smith' ) ,
( 'Amy', 'Johnson' ) ,
('Hannah', 'Williams' ) ,
( 'Michael', 'Brown' ) ,
( 'Sandy', 'Jones' ) ,
]
mycursor.executemany(sql, val)
mydb.commit()
print(mycursor.rowcount, "records inserted.")
# Close the database connection
if(mydb.is_connected()):
mycursor.close()
mydb.close()
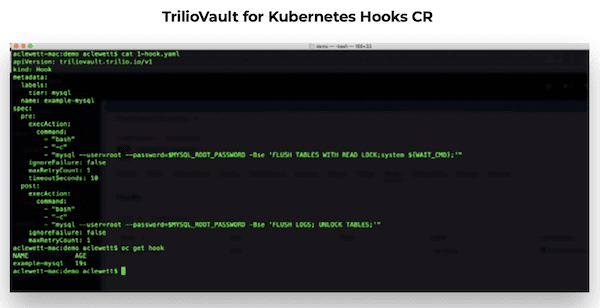
- Create Hooks
MySQL DB does not have its own built-in backup and restore capabilities. In order to maintain data consistency before backing up MySQL DB, you need to understand how the data is stored. For MySQL, DB backup data is stored in /var/lib/MySQL. This data directory stores the database schema, tables, configurations, policies, logs, and metadata. For backup, the scope can range from individual databases to tables, policies, metadata, etc. A backup creates a copy of the table and meta store data at that point in time and stores the copy in the specified target directory.
Use the FLUSH command on MySQL DB and UNLOCK TABLES to make sure you have a consistent state of data before the backup is triggered. A full backup creates a copy of the metastore and shared data. An incremental backup creates a copy of the only meta store and shard data that has changed since the last incremental backup. If there are no existing incremental backups, the system automatically performs a complete backup. Use the MySQL DB backup inside the Trilio for the Kubernetes backup hook.
apiVersion: triliovault.trilio.io/v1
kind: Hook
metadata:
name: mysql-hook
spec:
pre:
execAction:
command:
- "bash"
- "-c"
- "mysql --user=root --password=$MYSQL_ROOT_PASSWORD -Bse 'FLUSH TABLES WITH READ LOCK;system ${WAIT_CMD};'"
ignoreFailure: false
maxRetryCount: 1
timeoutSeconds: 10
post:
execAction:
command:
- "bash"
- "-c"
- "mysql --user=root --password=$MYSQL_ROOT_PASSWORD -Bse 'FLUSH LOGS; UNLOCK TABLES;'"
ignoreFailure: false
maxRetryCount: 1
timeoutSeconds: 10
$ kubectl create -f tvk-mysql-hook.yaml
- Create BackupPlan
In the backup plan, specify the resources you want to protect. It could be a complete namespace, label-based application, Helm chart, or an Operator.
Create a backup plan for mysql-qa applications deployed in the default namespace using labels.
apiVersion: triliovault.trilio.io/v1
kind: BackupPlan
metadata:
name: mysql-backupplan
spec:
backupNamespace: default
backupConfig:
target:
name: demo-s3-target
namespace: default
hookConfig:
mode: Sequential
hooks:
- hook:
name: mysql-hook
namespace: default
podSelector:
labels:
- matchLabels:
app: mysql-qa
regex: mysql-qa*
containerRegex: mysql-qa*
$ kubectl create -f tvk-mysql-backupplan.yaml
- Create Backup
As the name suggests, the yaml example below performs the backup operation by referencing the created backup plan shown above.
Schedule a backup using scheduleType: Periodic.
apiVersion: triliovault.trilio.io/v1
kind: Backup
metadata:
name: mysql-hook-helm-full-backup
spec:
type: Full
scheduleType: Periodic
backupPlan:
name: mysql-backupplan
namespace: default
$ kubectl create -f tvk-mysql-backup.yaml
- Restore to a different namespace, for example “restore-ns.” This needs to be created if it does not already exist.
Perform a restore operation into a different namespace, or any namespace on a different cluster, as you would in an application migration scenario.
The yaml definition below will restore the mysql-qa application to a different namespace on the same cluster using the backup created earlier.
apiVersion: triliovault.trilio.io/v1
kind: Restore
metadata:
name: mysql-helm-restore
spec:
backupPlan:
name: mysql-backupplan
namespace: default
source:
type: Backup
backup:
name: mysql-hook-helm-full-backup
namespace: default
target:
name: demo-s3-target
namespace: default
restoreNamespace: restorens
skipIfAlreadyExists: true
$ kubectl create -f tvk-mysql-restore.yaml -n restore-ns
Conclusion
When you use this procedure, backing up MySQL with TrilioVault for Kubernetes is easy. The backups are application and data consistent and use the ‘hooks’ feature, which allows you to perform any pre/post backup actions.
Furthermore, TrilioVault for Kubernetes provides a wide range of helpful features, including:
- Storing metadata and all application resources on a specified target
- Supporting Helm/label/Operators, S3 or NFS- based backup targets
- Providing application hooks to ensure data consistent backups
With all of these features, Trilio for Kubernetes provides a strong platform for enterprise-grade Database backups for MySQL (as well as many other databases).
Bhagirath Hapse, Solutions Engineer for Trilio
FAQs
I understand how to back up my MySQL database, but how do I ensure my other Kubernetes application components are also included in the backup for a complete recovery scenario?
TrilioVault for Kubernetes takes an application-centric approach to backups. This means it doesn’t just back up your MySQL database but also captures the Kubernetes objects (like deployments, services, etc.) and metadata that define your entire application. In the event of a full recovery, this holistic backup allows you to restore not just your MySQL data but also the surrounding components, enabling your application to resume seamlessly.
Can I use Kubernetes MySQL backups to migrate my application to a different Kubernetes cluster?
Yes, you can leverage your Kubernetes MySQL backups for migration. TrilioVault for Kubernetes allows you to restore backups to any namespace within the same cluster or even to different Kubernetes clusters altogether. This simplifies the migration process, ensuring your MySQL data and application settings transfer to the new environment.
The article mentions using hooks for data consistency. Could you elaborate on how these hooks work specifically in the context of Kubernetes MySQL backups?
Hooks are a mechanism within TrilioVault for Kubernetes that enable you to execute custom commands before and after a backup. For Kubernetes MySQL backups, a common use of pre-backup hooks is to ‘quiesce’ the database by issuing commands like FLUSH TABLES WITH READ LOCK, temporarily pausing writes. This ensures a consistent state of your MySQL data during the backup process. Post-backup hooks could then release these locks, resuming normal database operations.
Our database is quite large. How can I optimize Kubernetes MySQL backup performance to minimize the impact on my application?
TrilioVault for Kubernetes supports both full and incremental backups. After an initial full backup, you can schedule subsequent incremental backups that only capture the changes since the previous backup. This reduces the amount of data transferred and speeds up backup times, minimizing impact on your production MySQL database. Additionally, Trilio’s optimizations for handling metadata and its parallelization features contribute to overall backup performance.
Could you explain how I can monitor and get alerts on the status of my Kubernetes MySQL backups?
TrilioVault for Kubernetes provides robust monitoring capabilities. You can track the status of backup and restore operations through its web-based UI or by integrating it with your existing monitoring and alerting tools. Trilio can trigger alerts for successful completions, failures, or warnings, allowing you to proactively manage the protection of your MySQL data.
