


In this blog post, you will find out how to backup InfluxDB time-series databases to S3-compatible or NFS targets, and how to restore them.
InFluxDB Backup and Restore in Kubernetes
InfluxDB is an open-source time-series database developed by InfluxData. It is optimized for fast, high-availability storage and retrieval of time-series data for use with operations monitoring, application metrics, Internet of Things sensor data, real-time analytics, and more. InfluxDB is designed to handle high write and query loads.
Why Backup InfluxDB in Kubernetes?
Data loss is a serious problem. Losing files means losing time and money while you restore or recover information essential to the business. In the case of a server failure or outage, valuable data could be lost from the database forever. Losing files and documents often has a lasting impact on the company’s financial health. Consequently, backup and recovery are essential to the overall viability of the business.
The dynamic architecture of Kubernetes puts a lot of demands on a backup and recovery solution, so finding the right one can be difficult. In Kubernetes, applications are microservices-based and dynamic in nature. Applications can be deployed using labels, Helm charts, or Operators. There are also multiple namespaces and resources that are either tied to a specific namespace or common across all namespaces. As such, metadata is vital for application-centric backup.
Considering all of the above, you need to identify software that can provide an application-centric, cloud-native data protection solution. TrilioVault for Kubernetes (TVK) offers a platform that satisfies these requirements.
The image below provides a quick overview of how backup works in TVK:
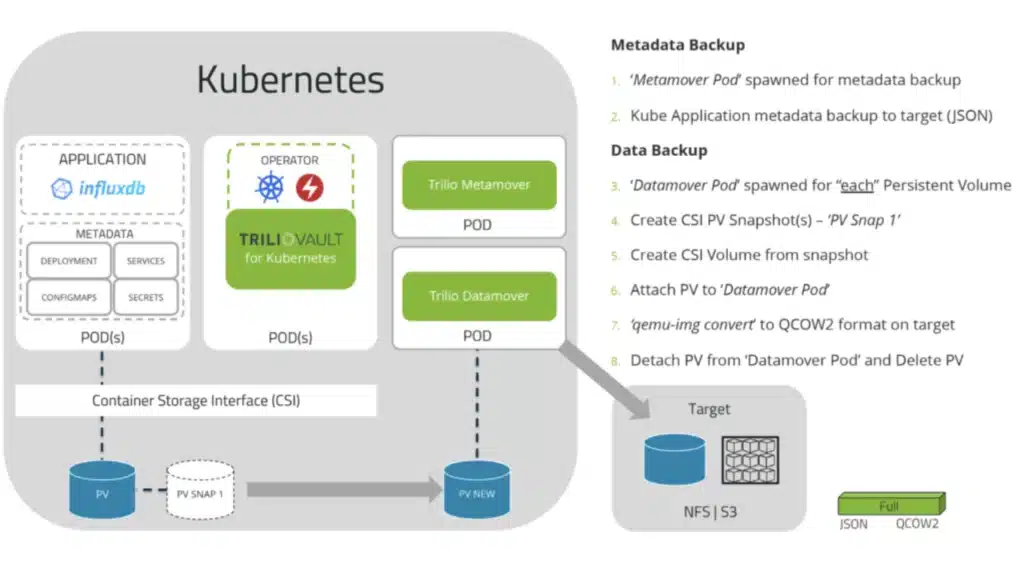
Now, take a look at how TVK performs application consistent backup and restore of InfluxDB.
Pre-requisite: Install Trilio for Kubernetes (T4K) and configure using the following steps:
- Install Test CSI Driver — Leverage the test hostpath driver if your environment does not support the driver with Snapshot capabilities today.
- Software Access and Installation — Access software and install it based on the specific directions for your environment.
- License — Leverage the Free Trial or Free Basic Edition by following instructions from the licensing page. If you already have an enterprise license, you can skip this step.
Create a target where backups will be stored
The Backup Target CRD specifies the backup storage media. TrilioVault supports either AWS S3-compatible object storage or NFS. All the backups created will be saved on the backup target specified in the Application CR spec. An Amazon S3 target example is provided below:
apiVersion: triliovault.trilio.io/v1
kind: Target
metadata:
name: demo-s3-target
spec:
type: ObjectStore
vendor: AWS
objectStoreCredentials:
url: "https://s3.amazonaws.com"
accessKey: "AaBbCcDdEeFf"
secretKey: "BogusKeyEntry"
bucketName: "S3_Bucket_US_East"
region: "us-east-1"
thresholdCapacity: 1000Gi
$ kubectl create -f tv-backup-target.yaml
InfluxDB databases can be deployed on Kubernetes using Helm charts. In the example below, a new release called my-release is created from helm chart bitnami/influxdb using the helm install command.
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm repo update
$ helm install my release bitnami/influxdb
Add Test Data
Let’s add some test data to the InfluxDB database. Please follow the commands below to create a test database, table, and records.
$ oc exec -it influxdb-deployment-54c5c78664-f7z7n -- influx
Connected to https://localhost:8086 version 1.7.4
InfluxDB shell version 1.7.4
Enter an InfluxQL query
>
>auth
username: xxxx
password: xxxx
>
>CREATE DATABASE pirates
>use pirates
Using database pirates
>INSERT treasures,captain_id=dread_pirate_roberts value=801
>INSERT treasures,captain_id=flint value=29
>INSERT treasures,captain_id=sparrow value=38
>INSERT treasures,captain_id=tetra value=47
>INSERT treasures,captain_id=crunch value=109
>
>SELECT * FROM treasures
name:treasures
time captain_id value
---- ---------- -----
1613634634180857624 dread_pirate-roberts 801
1613634654035942732 flint 29
1613634666125641798 sparrow 38
1613634676936723375 tetra 47
1613634694340402128 crunch 109
>
>exit
Create Hooks
Hooks enable the ability to inject commands into pods or containers before and after a backup via pre/post commands. As a result, customers can take application consistent backups of their applications.
- InfluxDB has its own built-in backup and restore capabilities. Their scope can range from individual databases to shards, policies, etc. A backup creates a copy of the metastore and shard data at a point in time and stores the copy in the specified directory.
- A full backup creates a copy of the metastore and shard data.
- An incremental backup creates a copy of whatever metastore and shard data has changed since the last incremental backup.
- If there are no existing incremental backups, the system automatically performs a complete backup.
- Use the InfluxDB backup command inside the TVK backup hook (see below).
apiVersion: triliovault.trilio.io/v1
kind: Hook
metadata:
name: influx-hook
spec:
pre:
execAction:
command:
- "bash"
- "-c"
- "bkpfile=/tmp/snapdate +%Y%m%dT%H%M; influxdbackup $bkpfile"
ignoreFailure: false
maxRetryCount: 1
timeoutSeconds: 10
post:
execAction:
command:
- "bash"
- "-c"
$kubectl create -f tv-influx-hook.yaml
Create BackupPlan
The BackupPlan specifies the backup job. The specification includes the backup schedule, backup target, and the resources to backup.
apiVersion: triliovault.trilio.io/v1
kind: BackupPlan
metadata:
name: influx-hook-label-backup-plan
spec:
backupNamespace: default
backupConfig:
target:
name: demo-s3-target
backupPlanComponents:
custom:
- matchLabels:
app:influxdb
hookConfig:
mode: Sequential
hooks:
- hook:
name: influx-hook
podSelector:
labels:
- matchLabels:
app: influxdb
regex: influxdb*
$kubectl create -f tv-influx-backupplan.yaml
Create Backups
The backup takes either a full or incremental backup of the resources specified in the BackupPlan spec. The first backup of the application will always be a full backup, even if the user specifies their backup type as incremental.
apiVersion: triliovault.trilio.io/v1
kind: Backup
metadata:
name: influx-hook-label-full-backup
spec:
type: Full
scheduleType: Periodic
backupPlan:
name: influx-hook-label-backup-plan
$kubectl create -f tvk-mysql-backup.yaml
$kubectl create -f tvk-mysql-backup.yaml
Schedule a demo to learn how Trilio can help you implement a flexible InfluxDB backup and restore strategy that aligns with your specific needs.
Restore InfluxDB in Kubernetes
The restore specifies which backup resources should be restored. Resources can be restored to the same namespace or to a different one. Let’s take a look at restoring to a different namespace, e.g. “restore-ns.” This needs to be created if it does not already exist.
apiVersion: triliovault.trilio.io/v1
kind: Restore
metadata:
name: influx-label-restore
spec:
backupPlan:
name: influx-hook-label-backup-plan
source:
type: Backup
backup:
name: influx-hook-label-full-backup
target:
name: demo-s3-target
restoreNamespace: restore-ns
skipIfAlreadyExists: true
$kubectl create -f tv-influx-restore.yaml
$kubectl create -f tv-influx-restore.yaml
Conclusion
When you use this procedure, backing up a time-series database like InfluxDB with TrilioVault for Kubernetes is as easy as it gets. The backups are application-consistent, and the “hooks” allow the user to perform any pre/post-backup actions. Furthermore, TrilioVault for Kubernetes provides a wide range of helpful features, including:
-
- Native Kubernetes application
-
- Stores metadata and all application resources to a specified target
-
- Supports application deployment types of Helm/Label/Operators and S3 or NFS-based backup targets
-
- Provides application hooks to ensure data-consistent backups
Altogether, TVK provides a strong platform for enterprise database backups.
For more information on Trilio for Kubernetes request a demo today.
FAQs
I see that Trilio for Kubernetes uses hooks for application-consistent backups. Could I use these hooks for other time-series databases besides InfluxDB?
Yes, Trilio for Kubernetes’s hooks provide a flexible mechanism for customizing the backup and restore process. As long as your time-series database offers a way to quiesce the database (e.g., temporarily pausing writes), dump data, or perform similar actions, you can integrate these commands into your pre and post hooks to ensure consistent backup and restore of InfluxDB, or any other time-series database.
Can I use Trilio for Kubernetes to schedule both full and incremental backups of my InfluxDB databases?
Yes, Trilio for Kubernetes supports full, incremental, and even on-demand backups. You can define schedules within your BackupPlan to automate a mix of full and incremental backups of your InfluxDB instances. This offers flexibility for optimizing storage usage and minimizing backup windows.
The article mentions restoring to a different namespace. Does Trilio for Kubernetes support other advanced restore scenarios, such as restoring specific databases or point-in-time restores within InfluxDB instances?
Trilio for Kubernetes offers granular control over your backup and restore of InfluxDB databases. You can choose to restore an entire InfluxDB instance, specific databases, or use Trilio’s capabilities to enable point-in-time restores for fine-grained recovery.
Our InfluxDB deployment is quite large, and we're concerned about backup performance. Does Trilio have any optimizations for large-scale InfluxDB instances?
Trilio for Kubernetes is designed with performance considerations for large deployments in mind. It leverages techniques like efficient metadata management, parallelization, and the use of incremental backups (where applicable) to minimize the impact on your InfluxDB environment during the backup and restore process. Additionally, you can work with Trilio experts to optimize your backup plans to match your performance requirements.
Could I integrate my existing CI/CD pipelines with Trilio for Kubernetes to trigger backups of InfluxDB during development or testing phases?
Yes, Trilio for Kubernetes’s API-driven approach makes it easy to integrate with your CI/CD tools. You can use the Trilio for Kubernetes API or command-line interface (kubectl plugin) to trigger on-demand backups of InfluxDB instances as part of your development and testing workflows, enabling you to quickly capture point-in-time snapshots for easy rollback or debugging.
