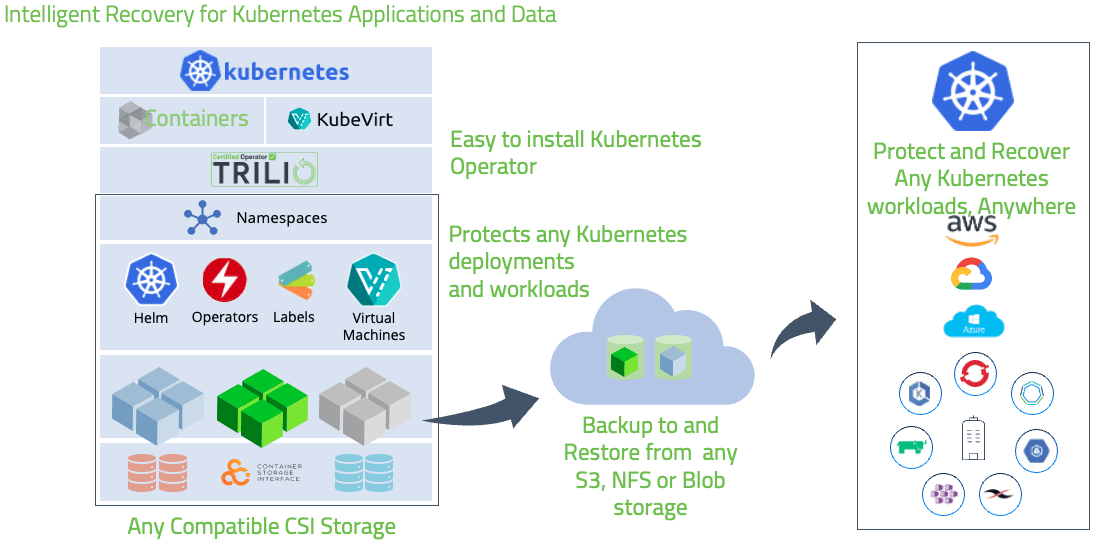
In today’s changing world, where data breaches and security incidents are becoming more common, safeguarding your valuable data has never been more important. As businesses increasingly rely on containerization for their applications Kubernetes has emerged as the go-to platform for managing and orchestrating containerized environments. However due to its distributed and dynamic nature Kubernetes poses challenges when it comes to safeguarding data.
This article delves into the significance of data protection in Kubernetes environments. Explores the risks and difficulties that organizations may face. From deletions to attacks the threat landscape is constantly evolving, underscoring the need for robust data protection strategies.
Our content plan encompasses topics aimed at helping you effectively secure your Kubernetes data. We will explore strategies for implementing backups and replication guarding against data loss encrypting information and leveraging disaster recovery solutions. Moreover we will delve into practices for securing your Kubernetes environment including access controls, vulnerability management and monitoring. By adhering to these guidelines you can ensure the confidentiality, integrity and availability of your data, within your Kubernetes infrastructure.
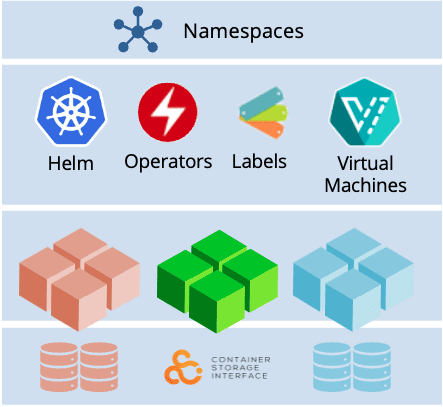
Data Security, in Kubernetes Environments using Trilio
As Kubernetes gains popularity as the container orchestration solution it becomes crucial to recognize the significance of safeguarding data in Kubernetes environments. TrilioVault, a cutting edge data protection solution tailored specifically for Kubernetes enables businesses to ensure the safety and integrity of their data.
Understanding the Nature of Data in Kubernetes and its Importance
Data plays a role in running and maintaining applications within Kubernetes environments. Each piece of data within a cluster from volumes to container configurations holds value. Therefore it is vital to implement strategies for data protection to mitigate the risks associated with loss or corruption.
Exploring the Unique Challenges Involved in Data Protection within Kubernetes Clusters
Protecting data in a Kubernetes environment presents its set of challenges. The dynamic nature and ephemeral characteristics of containers make it challenging to guarantee data availability and durability. Additionally the distributed nature of Kubernetes clusters necessitates an scalable data protection solution.
Overview of the Various Components Involved in Data Protection:
Data protection within Kubernetes encompasses components working together seamlessly to safeguard information. Persistent volumes serve as a storage layer: containers execute applications while storing data and configurations define container behavior.
It’s important to have an understanding of how these components work in order to effectively protect data.
- Persistent Volumes: These are responsible for providing storage resources to containers ensuring that data remains intact when the containers are no longer running.
- Containers: They serve as the platform for running applications and containing data. Safeguarding containers is crucial for protecting data.
- Configuration: Configurations involve specifying settings and parameters for containers ensuring their functionality and safeguarding the associated data.
With TrilioVault businesses can effectively tackle the challenges associated with safeguarding data in Kubernetes environments. Stay tuned to discover backup and recovery strategies, techniques for disaster recovery, encryption and security measures, storage solutions, compliance and governance practices, monitoring and auditing procedures disaster recovery testing and validation methods ways to prevent data loss, open source tools practices in the field real life case studies as well, as support and resources provided for Kubernetes data protection.
Backup and Recovery Strategies
Ensuring the protection of data, in a Kubernetes environment is of importance. Without strategies for backup and recovery organizations run the risk of losing data experiencing costly downtime and compromising their business operations. In this section we will delve into the significance of backup and recovery in safeguarding Kubernetes data and discuss recommended approaches to ensure the safety and availability of your data.
Significance of backup and recovery in protecting Kubernetes data:
Backup and recovery are components of a data protection strategy. In Kubernetes environments where applications and data are spread across containers and nodes, reliable backup and recovery solutions are more crucial.
A backup and recovery system acts as a safety net against data loss resulting from various factors such as accidental deletions, hardware failures, software glitches or security breaches. It empowers organizations to minimize the impact of incidents by restoring their operations.
Recommended practices for backing up Kubernetes data
When it comes to backing up Kubernetes data there are recommended practices that organizations should adhere to:
- Establish schedules: Automate the backup process to ensure consistent backing up of data, at predefined intervals.
- Make sure to create backups, for all components: It is essential to back up not only persistent volumes and containers but also the critical configuration files that define the desired state of your Kubernetes cluster.
- Use incremental backups: Implementing incremental backups can significantly reduce backup durations and storage requirements, as only the changes since the last backup are captured.
- Ensure that you have off site backups: Storing your backups off site or in a location guarantees that you can recover your data even in the event of a disaster.
Strategies for safeguarding volumes, containers and configuration
Protecting your volumes, containers and configuration files is crucial to maintaining data integrity and availability. Here are some strategies you should consider:
- Use replication and redundancy: Deploy replicas of applications and persistent volumes across nodes to provide redundancy and enhance fault tolerance.
- Implement access controls: Restrict access to data by using mechanisms like RBAC (Role Based Access Control) which helps prevent modifications and ensures data protection.
- Keep your Kubernetes environment regularly updated with patches: By staying up to date with security patches, for your Kubernetes environment you minimize vulnerabilities. Strengthen data protection.
Efficiently achieving backup and recovery in Kubernetes environments often requires the use of backup tools and the regular creation of snapshots
Here are some steps to consider:
- Select appropriate backup tools: Look for solutions specifically designed for Kubernetes that offer features like application backups, incremental backups, point in time recovery and integration with storage providers.
Take snapshots: Capturing snapshots of your Kubernetes resources enables you to restore data to specific points in time providing flexibility in data recovery scenarios.
When it comes to ensuring data availability and minimizing downtime through disaster recovery plans you should consider the following:
- Identify applications and data: Determine which applications and data are vital for your business operations and prioritize their recovery in case of a disaster.
- Define recovery time objectives (RTOs) and recovery point objectives (RPOs): RTO specifies the downtime while RPO determines the maximum acceptable data loss.
- Establish replication or backup mechanisms: Implement mechanisms like replication or backups to store copies of applications and data at a location. This allows for recovery, in case of a disaster.
- Regularly update your disaster recovery plan: Regularly conducting tests on your disaster recovery plan is crucial as it helps detect any shortcomings, ensures its efficiency and allows for adjustments to meet evolving conditions and needs.
By employing backup and recovery techniques companies can protect their Kubernetes data, uphold uninterrupted business operations. Minimize the vulnerabilities linked to data loss or system breakdowns.
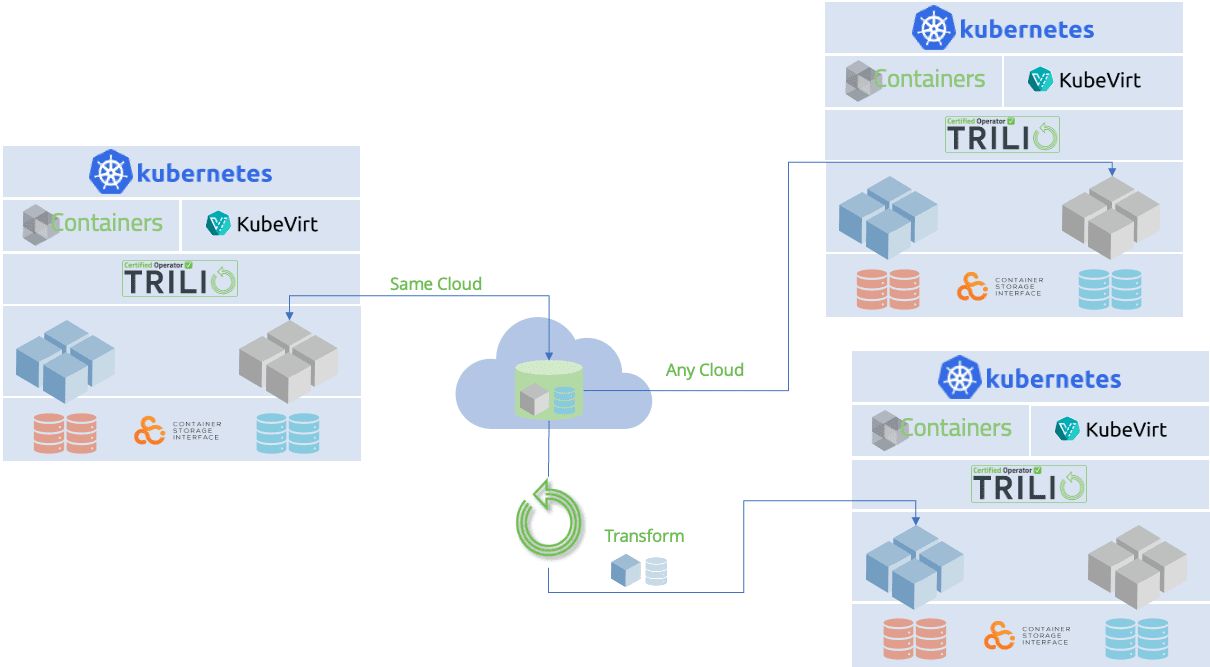
Techniques, for Dealing with Disasters
When faced with a disaster it is crucial to have techniques in place to ensure the integrity of data and minimize data loss in Kubernetes clusters. This section explores mechanisms and approaches that can be used for disaster recovery in Kubernetes.
An Overview of Disaster Recovery Mechanisms in Kubernetes Clusters
Kubernetes provides a range of built in mechanisms to assist in recovering from disasters. These mechanisms include strategies for backup and recovery failover capabilities, data replication and techniques that promote availability. Understanding these mechanisms is essential for implementing a disaster recovery plan.
Failover, Replication and High Availability Techniques for Data Recovery
Kubernetes offers capabilities that seamlessly switch components if one fails. Replication techniques enable the creation of copies of data to ensure redundancy. High availability techniques ensure continued access to data and applications during disastrous events.
Testing Recovery Procedures to Ensure Effectiveness
Regular testing of recovery procedures is crucial to validate their effectiveness and reliability. This involves simulating disaster scenarios and assessing the recovery procedures to identify any weaknesses or gaps within the system.
Importance of Testing and Simulation Exercises for Validating Disaster Recovery Procedures
Testing and simulation exercises play a role in validating disaster recovery proceduresThese exercises are designed to find weaknesses, improve the plans for recovery and make sure that systems are well equipped to handle events.
Monitoring and Auditing for Data Protection
Monitoring and auditing are crucial for ensuring data protection in Kubernetes environments. By monitoring data protection activities organizations can proactively. Mitigate potential security risks.
There are techniques for monitoring and tracking data protection activities in Kubernetes environments. These include keeping track of backup and recovery operations, encryption status and access controls. By implementing robust monitoring techniques organizations can gain insights into the health and security of their data.
Some common techniques for monitoring data protection activities include:
- Regularly checking the status of operations to ensure that critical data is adequately protected.
- Monitoring the encryption status of data in time to ensure the security of information.
- Conducting audits of access controls to identify access attempts and potential breaches.
The significance of logging and monitoring tools, in Kubernetes environments cannot be overstated.
Logging and monitoring tools are components of any Kubernetes data protection strategy. These tools provide organizations with visibility into the activities and events happening within their Kubernetes clusters.
By utilizing logging and monitoring tools organizations can achieve the following objectives:
- Detecting and investigating security incidents: Log data enables tracing the root cause of security incidents facilitating actions to prevent occurrences in the future.
- Monitor performance and resource utilization: Monitoring tools aid in identifying any irregularities or unusual patterns in resource usage allowing organizations to optimize their Kubernetes environment effectively.
- Ensure compliance with requirements: Logging and monitoring data serve as evidence of adherence to data protection regulations and policies.
Implementing auditing mechanisms for detection of security incidents
The implementation of auditing mechanisms plays a role in identifying and addressing security incidents. Audits enable organizations to track and analyze system activities, detect access attempts and ensure compliance with data protection policies.
Key steps involved in implementing auditing mechanisms within Kubernetes environments include:
- Defining audit policies: Clearly establishing the scope and objectives of auditing activities assists organizations in adopting an approach towards safeguarding data.
- Enabling audit logging: Enabling audit logging captures records of activities occurring within the Kubernetes environment offering insights for investigating security incidents thoroughly.
- Analyzing audit logs: Regularly analyzing audit logs aids in identifying any activities or deviations from established security policies.
Utilizing anomaly detection for potential data protection breaches identification
Anomaly detection serves as an approach, towards identifying data protection breaches within Kubernetes environments.
By examining patterns and behaviors companies have the ability to identify deviations from activities. This allows them to take action in order to prevent data breaches.
There are methods for detecting anomalies in Kubernetes environments:
- Utilizing machine learning algorithms: This approach can assist in identifying patterns or behaviors that might indicate a breach of data protection.
- Conducting analysis: By analyzing user behavior access patterns and network traffic it becomes possible to detect any activities that could pose a risk to data protection.
- Implementing real time monitoring: Continuously monitoring the flow of data and system activities, in real time empowers organizations to immediately identify anomalies and take actions.
Protecting Data in Kubernetes using Trilio
Data loss prevention is incredibly important, in a Kubernetes environment to safeguard the security and reliability of your information. TrilioVault offers a solution for data protection in Kubernetes with features designed to mitigate the risks associated with data loss.
Measures to Prevent Data Loss or Corruption
To avoid data loss or corruption in Kubernetes it’s essential to implement measures. TrilioVault allows you to create backups of your data ensuring that you always have a restore point in case of any unfortunate events. By scheduling automated backups TrilioVault eliminates the risk of error. Guarantees continuous protection for your data.
The Significance of Data Integrity Checks and Error Detection
Maintaining data integrity is crucial for ensuring the accuracy and dependability of your information. During the backup and restore processes TrilioVault conducts data integrity checks to identify any errors or corruptions. By detecting and alerting you about any discrepancies TrilioVault enables action that prevents further damage and preserves the integrity of your valuable data.
Proactive Monitoring for Detecting Anomalies and Early Warning Signs
Detecting anomalies and early warning signs, in a manner can significantly reduce the risk of data loss.TrilioVault offers monitoring capabilities that continuously analyze your Kubernetes environment for any behaviors. With real time alerts and notifications TrilioVault empowers you to promptly address any issues ensuring the safety and availability of your data.
Here are some important considerations to ensure data protection in Kubernetes
To safeguard the security and integrity of your data it is crucial to avoid pitfalls. TrilioVault provides guidance and best practices that will help you navigate these challenges effectively. By following the recommendations offered by TrilioVault you can establish a reliable data protection strategy ensuring the safety of your information, from potential risks.