
Trilio’s repository of important documents, overviews, release notes, documentation, etc…

With ever-evolving advances in technology, new regulations for data privacy, and the drive to grow the business, it is critically important for the telecommunications industry to have a comprehensive disaster recovery plan, especially for important next-generation services such as 5G.
There are a number of methods for disaster recovery, such as backup and replication; and, there are tremendous benefits to addressing these requirements intelligently using modern technological approaches.
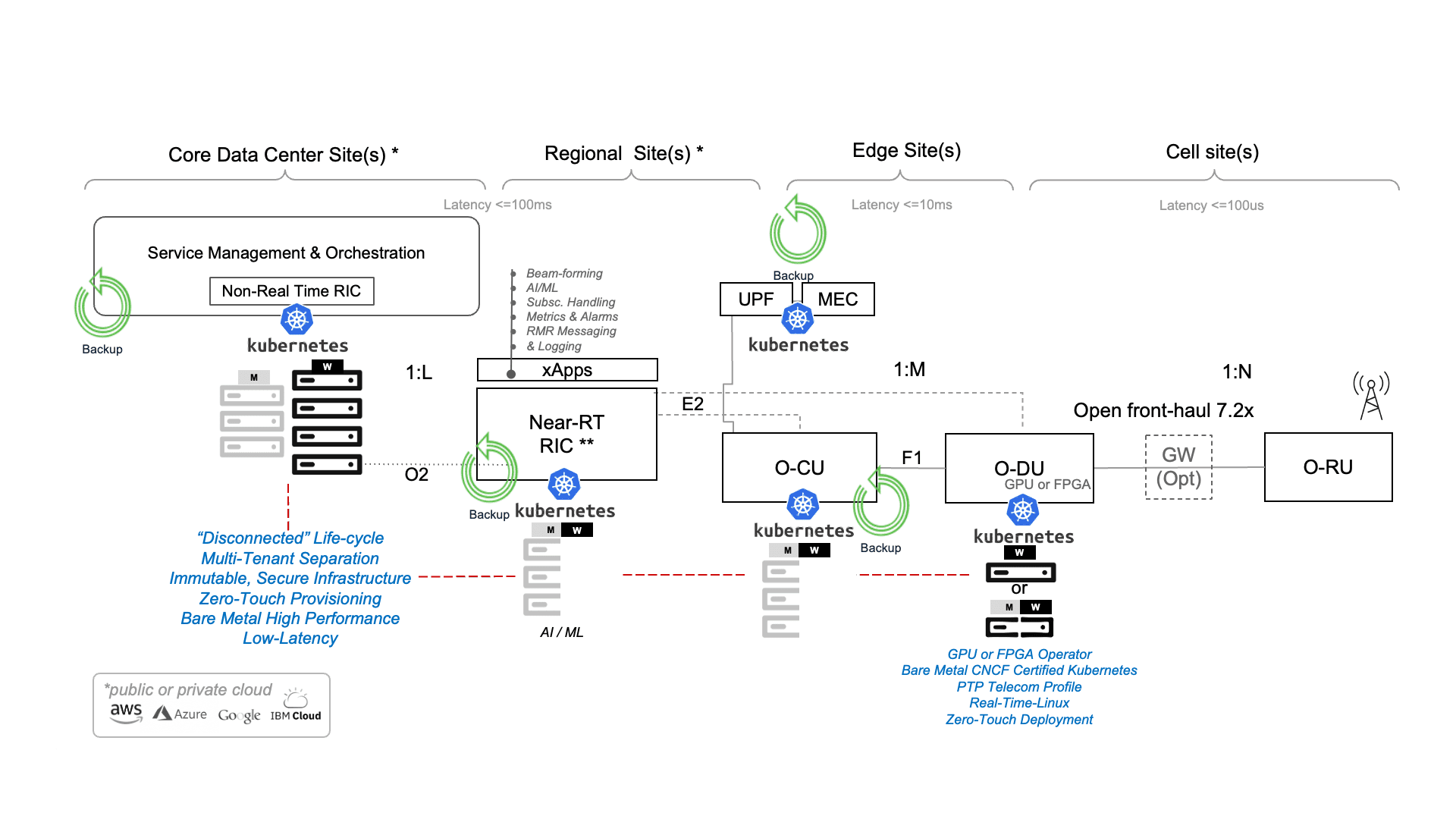
5G technology is revolutionizing the telecommunications industry. With 5G, users are able to access data at unprecedented speeds and receive much better coverage, coupled with low latency, improved network stability, and reliability. 5G infrastructure opens up the adoption of a wide range of new applications such as virtual reality, augmented reality, machine-to-machine communication, Industry 4.0 enablement, IoT usage, the promise of autonomous driving vehicles, and the development of smart cities – where all devices and systems in an area are connected and can communicate with each other.
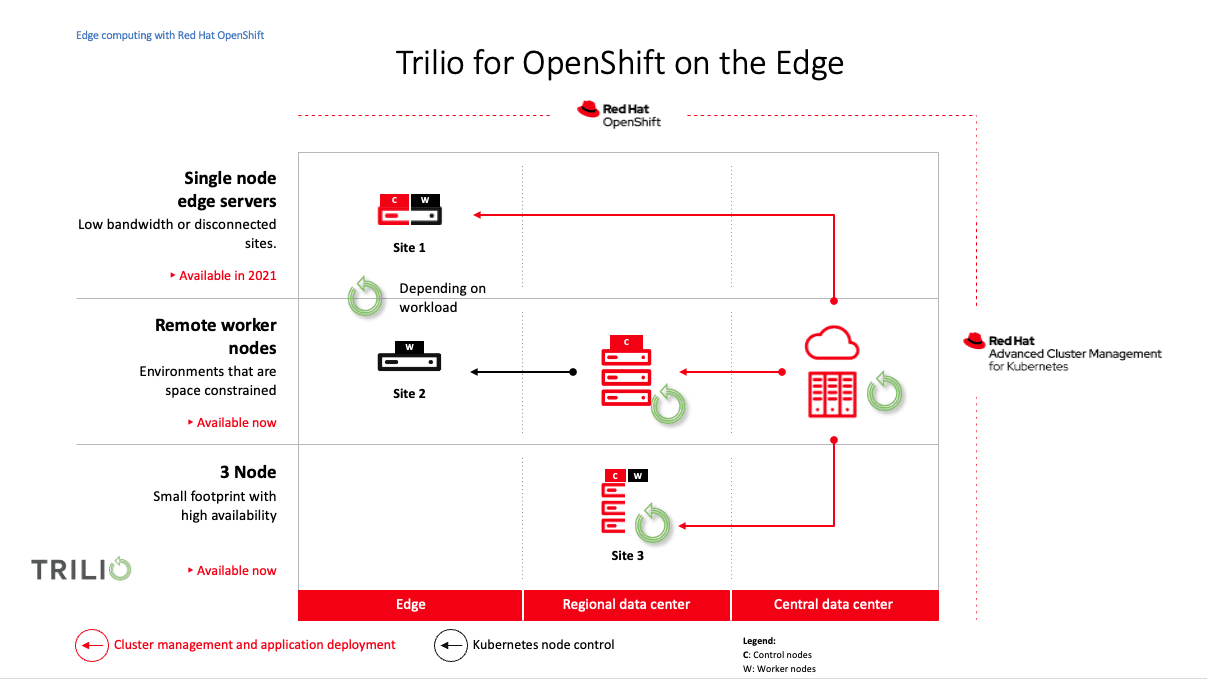
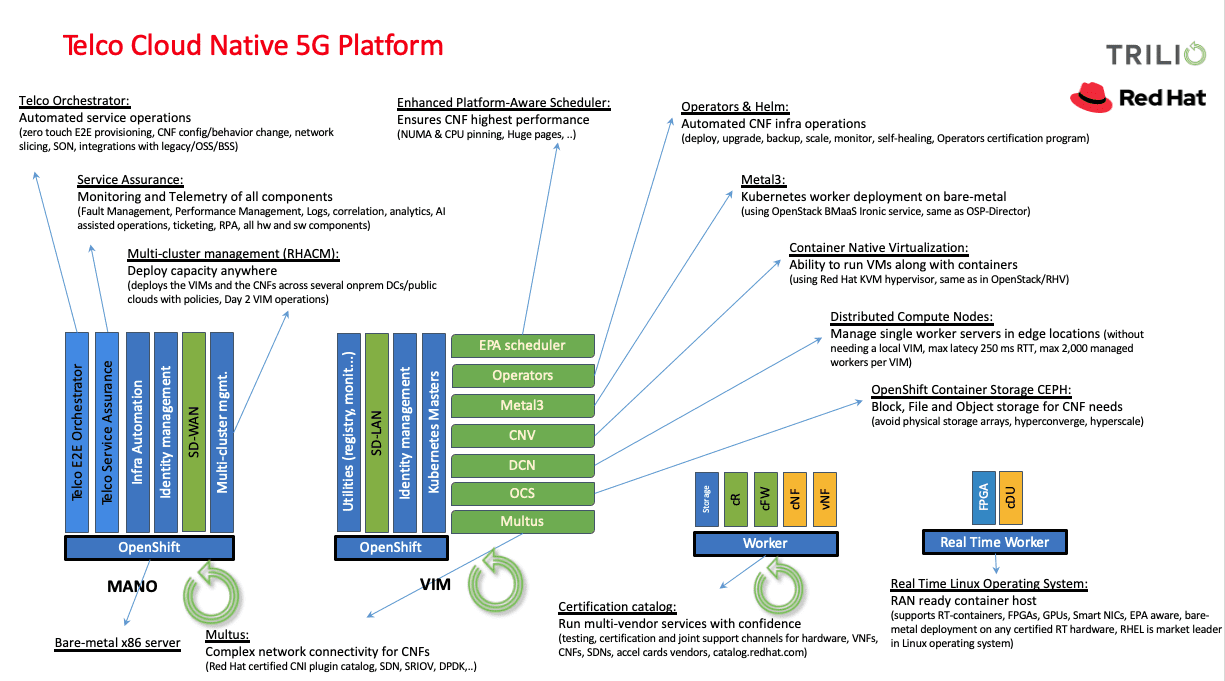
5G networks are agile, mandating scalable, flexible, and agnostic components from ecosystem partners in its Software Defined Architecture (SDA). Deployed in conjunction with orchestration frameworks such as Kubernetes, important abstracted infrastructure such as Cloud-Native Network Functions (CNFs) follow cloud-native architectural and operational principals to improve scalability and availability, while enabling automation and improved management without the need to physically reconfigure any. With a common and shared data layer and other automated and streamed services, resiliency and intelligent recovery are critical to ensure the service continuity of these complex networks.
Hyperscalers such as Amazon, Microsoft, and Google are partnering with telecommunication operators to provide access to high-capacity data centers and storage solutions, providing edge computing while reducing ongoing infrastructure investments. They enable operators to process data and provide development platforms to quickly build, deploy and manage other cloud-native applications efficiently. This has led to productized offerings such as Wavelength from AWS, Azure Edge Zones from Microsoft, Anthos for Telecom from Google Cloud, and a number of Opensource applications and initiatives.
Together with the hyperscalers, services now extend farther than ever. As a result, the surface area of an organization and potential attack vectors continue to grow inviting bad actors. More than ever, the combination of both environments requires applications to have greater mobility, availability, and resiliency, thus ensuring adherence to a multitude of governance and compliance regulatory frameworks.
According to Uptime’s “2022 Data Center Resiliency Survey,” the most common causes of downtime in organizations include:
For industries where reliability is the key driver of operations, data protection, and intelligent recovery quickly become the lynchpin for business assurance. With the complexity of 5G networks, the following components require fast and reliable recovery of Metadata, Configurations, and Data to ensure uptime of service or operations:
“Must Haves” in Order to be Resilient
Application resiliency is a critical part of your business continuity plan and is even more important now that infrastructures are increasingly diverse and complex. For example, if you use multiple clouds, a resilient infrastructure gives you the flexibility to restore your data from one cloud to another or move between distributions quickly. That agility is critical to resiliency because it can speed up your Recovery Time Objectives (RTO). Therefore, resilient applications can:
Unify your infrastructure -With so many computing platforms and storage solutions, you might be accidentally siloing your distributed environment. Break down these walls by allowing your applications and data to move between them.
While leveraging the agility that CNFs provide, it is critical to have an intelligent solution that is native, agnostic, flexible, and scalable. A solution that provides:
Quickly restore your applications from any cloud, storage, or distribution to maximize uptime. Stay resilient.
Compliance, please meet Trilio.


A simple contact us form
"*" indicates required fields
Customers in telecom, defense, automotive and financial services leverage Trilio to recover from disasters, migrate workloads, move workloads to new infrastructure and migrate to new software distributions.

Trilio is a leader in cloud-native data protection for Kubernetes and OpenStack environments.
Powered by Trilio