With ever-evolving advances in technology, new regulations for data privacy, and the drive to grow the business, it is critically important for the telecommunications industry to have a comprehensive disaster recovery plan, especially for important next-generation services such as 5G.
There are a number of methods for disaster recovery, such as backup and replication; and, there are tremendous benefits to addressing these requirements intelligently using modern technological approaches.
Introduction
5G technology is revolutionizing the telecommunications industry. With 5G, users are able to access data at unprecedented speeds and receive much better coverage, coupled with low latency, improved network stability, and reliability. 5G infrastructure opens up the adoption of a wide range of new applications such as virtual reality, augmented reality, machine-to-machine communication, Industry 4.0 enablement, IoT usage, the promise of autonomous driving vehicles, and the development of smart cities – where all devices and systems in an area are connected and can communicate with each other.
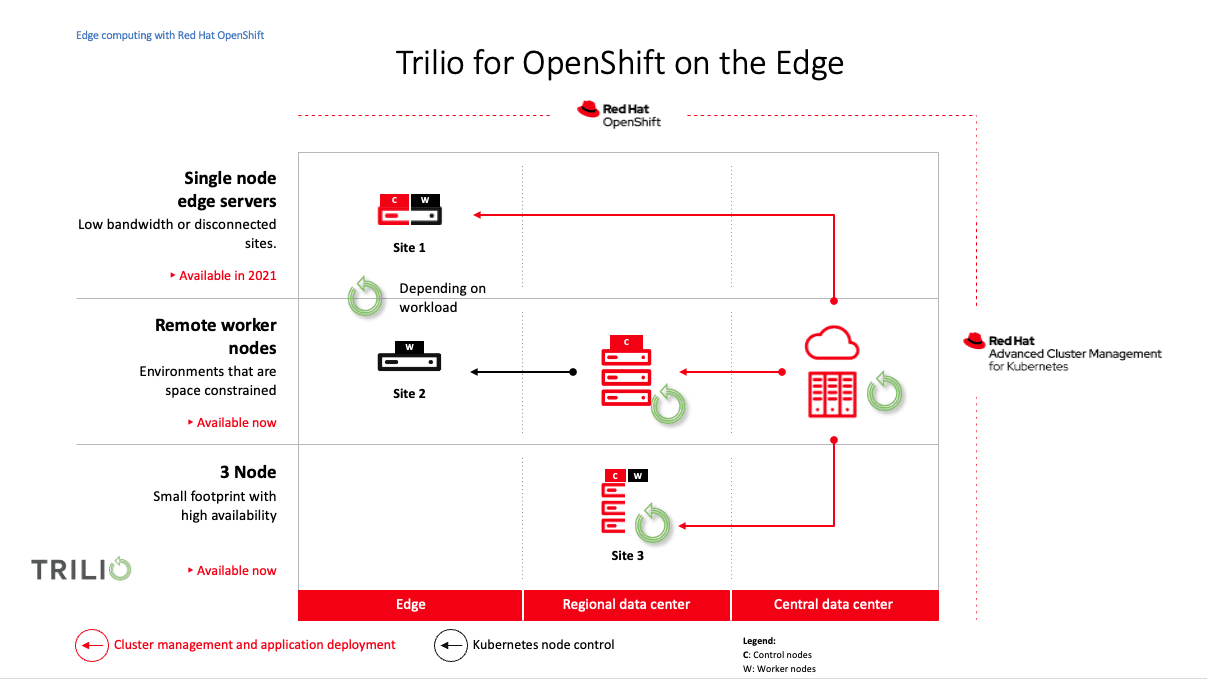
Trilio for OpenShift in an Edge deployment
Software Defines Everything!
5G networks are agile, mandating scalable, flexible, and agnostic components from ecosystem partners in its Software Defined Architecture (SDA). Deployed in conjunction with orchestration frameworks such as Kubernetes, important abstracted infrastructure such as Cloud-Native Network Functions (CNFs) follow cloud-native architectural and operational principals to improve scalability and availability, while enabling automation and improved management without the need to physically reconfigure any. With a common and shared data layer and other automated and streamed services, resiliency and intelligent recovery are critical to ensure the service continuity of these complex networks.
The Future is Hybrid from Core to Edge
Hyperscalers such as Amazon, Microsoft, and Google are partnering with telecommunication operators to provide access to high-capacity data centers and storage solutions, providing edge computing while reducing ongoing infrastructure investments. They enable operators to process data and provide development platforms to quickly build, deploy and manage other cloud-native applications efficiently. This has led to productized offerings such as Wavelength from AWS, Azure Edge Zones from Microsoft, Anthos for Telecom from Google Cloud, and a number of Opensource applications and initiatives.
Together with the hyperscalers, services now extend farther than ever. As a result, the surface area of an organization and potential attack vectors continue to grow inviting bad actors. More than ever, the combination of both environments requires applications to have greater mobility, availability, and resiliency, thus ensuring adherence to a multitude of governance and compliance regulatory frameworks.
Data Protection and Disaster Recovery to the Rescue
According to Uptime’s “2022 Data Center Resiliency Survey,” the most common causes of downtime in organizations include:
Human Error: Almost 40% of organizations in the last 3 years experienced significant outages due to human error or lack of testing recovery.
Network Issues: Problems relating to networking were the #1 cause of reported downtime over the last 3 years.
Cyber Attacks: Nearly 2 in 5 instances of downtime were caused by cyberattacks. About 40% of organizations worldwide suffered from some kind of ransomware attack in 2021.
Other Causes Include:
Power Outages
Natural Disasters
Hardware Failures
For industries where reliability is the key driver of operations, data protection, and intelligent recovery quickly become the lynchpin for business assurance. With the complexity of 5G networks, the following components require fast and reliable recovery of Metadata, Configurations, and Data to ensure uptime of service or operations:
Orchestration, Automation, and other Microservice Delivery Frameworks
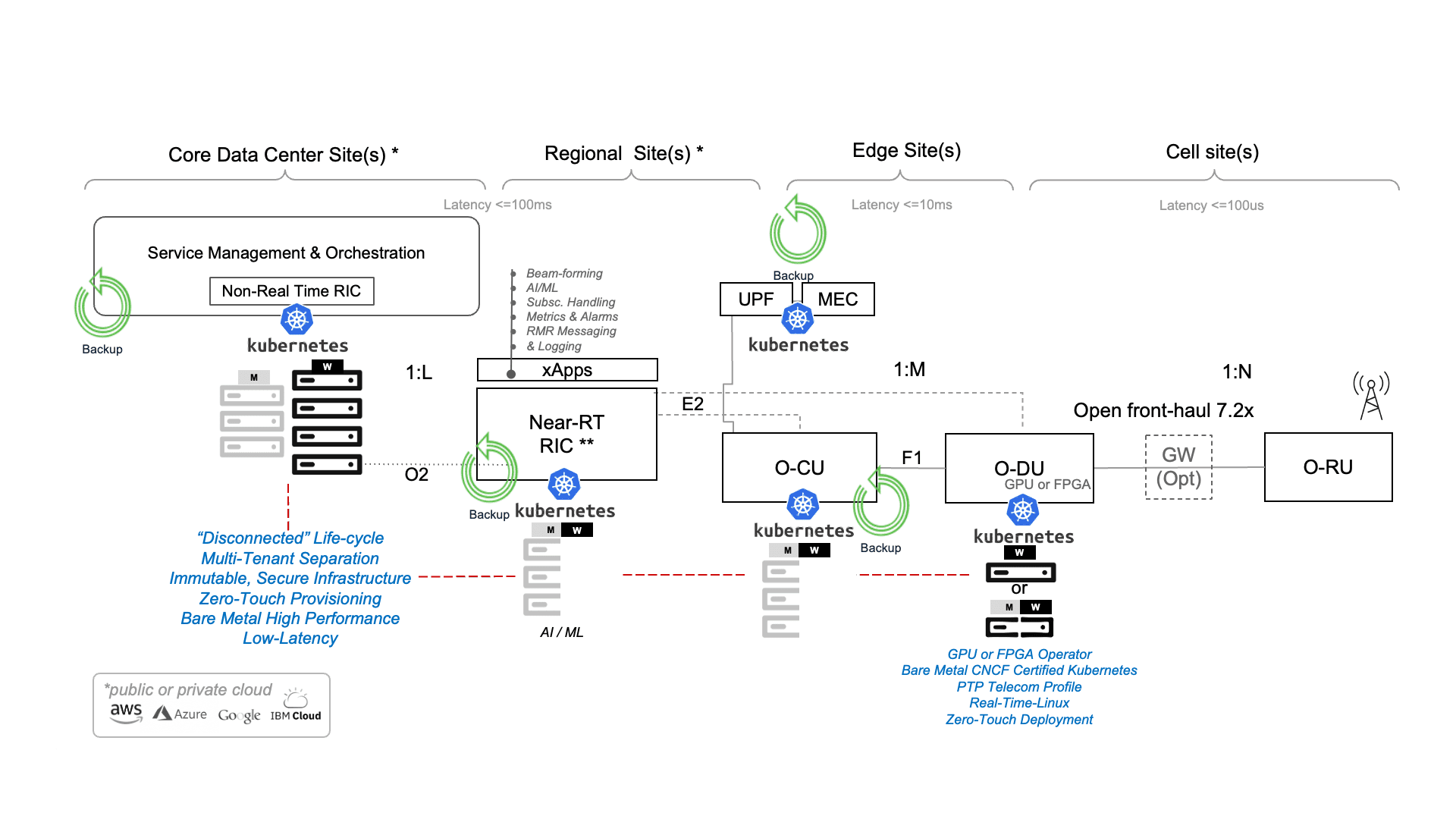
Trilio in Open Ran Deployment
“Must Haves” in Order to be Resilient
Application resiliency is a critical part of your business continuity plan and is even more important now that infrastructures are increasingly diverse and complex. For example, if you use multiple clouds, a resilient infrastructure gives you the flexibility to restore your data from one cloud to another or move between distributions quickly. That agility is critical to resiliency because it can speed up your Recovery Time Objectives (RTO). Therefore, resilient applications can:
Run successfully in production without errors.
Shift to different environments or infrastructures if and when they need to.
Be recovered or restored into another cloud quickly and efficiently.
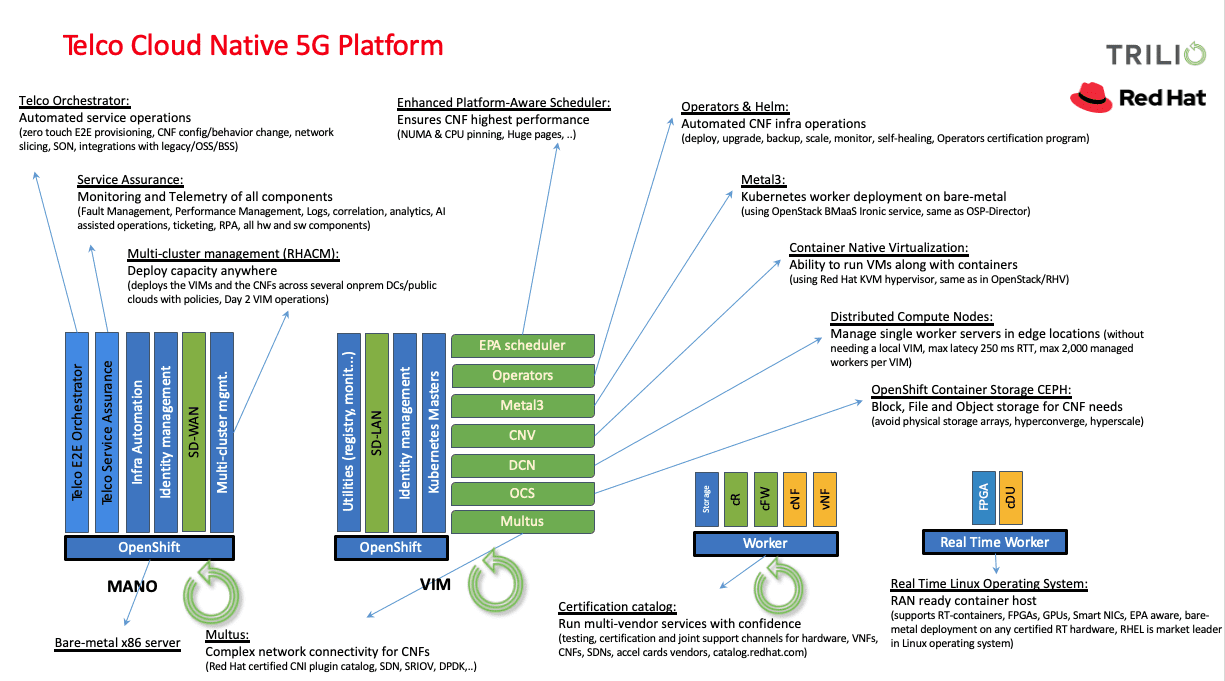
Trilio integration to protect a 5G deployment
The Future of Disaster Recovery is Here
Unify your infrastructure -With so many computing platforms and storage solutions, you might be accidentally siloing your distributed environment. Break down these walls by allowing your applications and data to move between them.
Migrate, replicate, and restore data and metadata to any storage, cloud, or distribution.
Continuously stage data in multiple, heterogeneous clouds.
Bring applications online in seconds, no matter where you run them or store their data.
While leveraging the agility that CNFs provide, it is critical to have an intelligent solution that is native, agnostic, flexible, and scalable. A solution that provides:
Application-centric Backup: Your platform should back up both data and metadata. Metadata includes important context for how your application is constructed and helps you efficiently get back to your last known good state.
Policy-based Recovery: Actively monitor the application for outages and automatically recover the application based on the policy settings.
Continuous Testing of Recovery: Look for a tool that lets you create your own disaster recovery plans, including backing up and restoring across clouds or distributions or in multiple namespaces. These workflows help you implement best practices and meet your compliance objectives. Organizations must have the ability to test DR plans regularly without impacting production.
Instant Recovery: Continuously stages backup data to production clusters so applications can be recovered instantly and organizations can achieve significant improvements in RTOs.
Recovery at Scale: As part of the cloud-native journey, organizations will continue to deploy multiple Kubernetes clusters in different clouds. Orchestrating a recovery when disaster strikes as the complexity of a cloud-native platform grows becomes extremely challenging. Integration with scalable automation tools such as Red Hat Advanced Cluster Management (RHACM) is a must to achieve recovery at scale.
Object level Recovery: Users must have the ability to recover not just entire applications but any artifacts of an application, including files, directories, or volume.
Quickly restore your applications from any cloud, storage, or distribution to maximize uptime. Stay resilient.
With more than 20 years of business management and executive leadership expertise, David is responsible for strategic partnerships, business development and corporate development of the company.