
Infrastructure as Code: What Is It and Why Do We Need It?
Infrastructure as Code (IaC) is the ability to manage and operate infrastructure components via code (CLIs/APIs) instead of using Graphical User Interfaces (GUI) or any other click-driven, visual methodologies. IaC applies to hardware components as well as software components within the three pillars of information technology: servers, storage, and networking.
The concept of Infrastructure as Code is not new and users have been writing scripts to manage and operate software technologies for a long time now. However, the ability to support IaC end-to-end on a product or solution is now a requirement for any business looking to accelerate its digital transformation. A good analogy for this growing need is Newton’s Second Law of Motion — for every action, there is an equal and opposite reaction.
![]()
People are innovating at a rapid pace and employing specialized technology hardware and software solutions to achieve specific use cases. Many solutions are custom systems that are built and sold by various vendors. As a result, there is a lot of potential in the power and simplification that IaC delivers. However, the management, operations and maintenance burden of multiple disparate solutions is increasing and can hamper productivity gains.
The complexity and effort required to effectively manage and fully control these environments individually is quickly growing beyond the capacity of even the most mature IT development and operations teams. Hence, large-scale management and automation is now required to handle purpose-built infrastructure systems. Support for API/CLI libraries is essential for this, since they make it possible to operate the entire infrastructure via code.
The proliferation of cloud computing and cloud-native architectures, such as Kubernetes, means applications and services are now broken down into smaller components to achieve granular levels of scalability, portability and application control. However, each microservice is practically impossible to manage and configure independently. Full-scale automation of services is required to be successful. Without automation, the sheer number of resources required to maintain an IT landscape will be too costly to realize the true benefits of a cloud-native design.
This is evident in the rise of new paradigms, known as ‘GitOps,’ within the microservices space. GitOps can be described as using a Git server to store code for building infrastructure (clusters, apps, etc.). All of the operations are executed on the Kubernetes cluster and managed by pushing code to the Git repository instead of making direct changes to the cluster itself. Using Git as the central source of truth provides a lot of benefits, including RBAC-based merges, approvals, auditing by various teams, and many more. However, even with these new innovative build/deployment paradigms, there are still new use cases being created concerning point-in-time data capture that goes beyond traditional backup and recovery.
Visit the webinar for a walkthrough on protecting, restoring, and using production data to improve software with the TVK GitHub Actions Runner.
Learn how to:
- Test production data in containers running across multi-cloud environments
- Capture the current production landscape and application running state before deployment
- Recover and migrate Kubernetes-based applications to new environments or across cloud infrastructure
GitHub Actions and Kubernetes Operational Needs
GitHub is a leading version control and source code management system that is used heavily by organizations of all sizes and has become one of the primary systems leveraged for GitOps. As part of its framework, GitHub provides actions or runners that perform tasks based on events. Runners are a core aspect of software development and associated operational processes that utilize the power of IaC. For example, runners enable the execution of integration activities to create a deployable packaging of code for testing purposes, all of which is triggered upon code check-in by a developer. With Kubernetes application development and deployment, runners provide a lot more flexibility as they are all microservices-based and managed via code (IaC). In terms of the application lifecycle from development to production, dev teams want to automate a lot more use cases now because of the new practices, such as microservices, being employed.
Real-world Kubernetes practices show that, as part of application lifecycle management, dev and application teams want to test using the most recent copy of production data in multiple test environments in order to increase the success of deploying applications into production. Since a lot of Kubernetes components get created at runtime, not defined in Git, dev and application teams want to capture the running state of their apps. This means that, in the event of corruption or app outages, they can quickly recover and triage the root cause of the failure. They even want to ensure that their IaC tools (ex: GitOps) can be recovered in case of failure. Similarly, for migration and business continuity purposes, operations teams want to be able to migrate applications from one cloud to another based on cost or performance. Trilio’s cloud-native Data Protection platform, TrilioVault for Kubernetes (TVK,) makes this all possible.
Introduction to Trilio for Kubernetes (T4K) and T4K GitHub Actions Runner
Applications built on Kubernetes use a completely different architecture. TVK is a purpose-built, cloud-native platform that enables users to capture entire Kubernetes applications (data and metadata) and mobilize them across different environments. This provides use cases such as multi-cloud migrations, point-in-time (PIT) recovery, Disaster Recovery, test/dev management and many more. Trilio also makes these use cases possible via GitOps/IaC by ensuring that the entire product can be managed and operated fully through code. Trilio has integrated its platform completely into the Kubernetes API server, making it extremely simple for users to get started, since they do not have to learn anything new. All they have to do is continue leveraging their existing Kubernetes API constructs to manage TVK.
To help customers in their modernization journey, Trilio has developed a TVK GitHub Actions Runner that combines its value with IaC to deliver application lifecycle use cases. The TVK runner solves the following needs for developers, DevOps engineers and Site Reliability Engineers (SREs):
- Day 0 (Dev) — Provides the ability to test with the most recent copy of production data in homogeneous or heterogeneous Kubernetes test environments that can be running in the same or different cloud environments to increase the success of moving from development to production.
- Day 1 (Dev/SRE) — Enables the capturing of the current production landscape before deploying new code to production. Also, offers the ability to capture the running state of an application for penetration testing, troubleshooting, or any other compliance reasons. This protects GitOps tools from having outages themselves.
- Day 2 (SRE) – Provides the ability to recover and migrate entire applications and workloads to newer environments or across cloud infrastructure as defined by corporate policies.
Watch this video to learn more about July 2021, GitHub Demo Days: Accelerate Cloud-Native Application Delivery with GitHub Runner by Trilio
Further Details: T4K GitHub Actions Runner
The objective of the TVK GitHub Actions Runner is to capture a point-in-time copy of Kubernetes applications (data and metadata) and reproduce that application in various environments for data management use cases.
The TVK GitHub Runner is self-hosted and takes inputs in terms of the source/destination of the Kubernetes cluster API server, backup storage location, storage classes, and the capture footprint including helm charts, operators, labels, or namespaces.
Architecture Diagram:
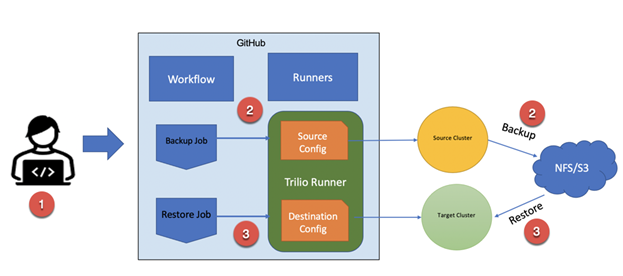
The TVK GitHub Actions Runner executes a GitHub workflow that performs two jobs (backup and restore) when a repository receives a push or a pull request.
- User checks-in code or merges a pull request.
- The backup job performs a backup of the given namespace from the source cluster. This backup gets stored on the backup target (storage media, S3 compatible object storage or NFS).
- The restore job runs a restore operation on the destination cluster and recreates the backed-up data (applications, namespace) on the destination cluster in the given namespace from the target (same target as the source cluster).
- Different storage classes that may be in use in the source and destination clusters are supported via TVK transforms.
Conclusion
With the rapid innovation in cloud and software-based infrastructure and the proliferation of multiple software technologies, management and automation is key for success. Automation can only be possible via IaC. With the rise and continued adoption of Kubernetes, microservices and IaC are the future. Any technology entering the IT market must enable operations and control via code. TrilioVault is a purpose-built platform providing point-in-time management and recovery for cloud-native applications.
Trilio can support the application lifecycle from Day 0 to Day 2 by enabling the key users in the development and operations teams to achieve their objectives leveraging IaC. The TVK GitHub Actions Runner is offered as a starting point for customers, but can be extended by adding more features (via the API). For example, operations teams who are more focused on automation activities can extend the runners to handle an array of applications instead of point applications.




