Backups are fundamental to data protection and recovery, but traditional backup methods and solutions are unsuitable for modern applications running on cloud-native infrastructure platforms like OpenStack. If you run your applications on OpenStack, you need to select an OpenStack backup solution that works natively, is multi-tenant, provides self-service, and makes application-centric backups.
In this article, we look at how workloads running on OpenStack have different backup requirements than traditional workloads. We go over what to back up, outline what features and capabilities to look for in a backup solution, and provide a comparison of popular solutions to help you make an informed decision when choosing an OpenStack backup solution.
Note that the article focuses on protecting applications and workloads running on OpenStack and not on protecting OpenStack itself.
Summary of key attributes in an OpenStack backup solution
OpenStack is a cloud-native platform and requires a cloud-native backup solution. The table below provides a list of essential features and capabilities to look for when choosing an OpenStack backup solution.
Feature | Description |
Application-centric | An application-centric backup captures both data from an application and its associated metadata. |
Agentless | An agentless design provides faster onboarding of workloads for protection, has less performance impact, and requires fewer resources. It enables a non-disruptive approach to backups both for deployment and operations. |
Multi-Tenant | Support for multi-tenancy ensures that multiple projects within an OpenStack implementation can each have their own backup policies while maintaining control through role-based access control. |
Self-Service | A self-service OpenStack backup solution allows authenticated and authorized users to back up and recover through the Horizon UI or the OpenStack CLI. This is similar to how self-service works natively in OpenStack for resource creation, such as instances. |
Scalable | The backup solution needs to scale with the platform while not requiring additional adjustments or configuration and without experiencing performance degradation. |
Integrated | An integrated backup solution uses APIs and runs like any other OpenStack service, such as Nova, Cinder, etc. |
Understanding backup and recovery in OpenStack
Why protect OpenStack?
It’s important for all organizations to acknowledge the importance of backups. Let’s start with a quick rundown of these benefits, tailored for OpenStack, before exploring the difference between protecting OpenStack workloads and traditional workloads:
- Data and metadata protection: One of the primary objectives of backups is data protection. A reliable backup of an instance or a volume snapshot ensures that users can restore data in the event of an incident such as corruption, accidental deletion, or complete infrastructure failure. Additionally, since OpenStack is a multi-tenant environment and applications are abstracted from the underlying resources, protecting both metadata and configuration is essential to ensure that the application works.
- Recovery: By design, OpenStack has a modular and distributed architecture. There are many moving parts, and these components can occasionally fail. An OpenStack installation with failed, unusable, or nonexistent backups will result in an expensive recovery operation in case of a failure or disaster. Protecting OpenStack with backups provides a way to quickly restore an instance to another working node or another cluster. Backups can also be used for file/folder-level recovery and to facilitate disaster recovery in extreme cases.
- Speed and agility: These are cloud-native characteristics—it is common for businesses to constantly aim to launch new products faster, release updates more quickly, and generally try to be more agile. Errors, security incidents, and disasters are bound to happen when you make changes at high speed; being able to recover quickly limits the impact of these incidents.
- Compliance requirements: Complying with regulations is an essential business requirement. Many regulations mandate data protection and require data backup policies. For example, HIPAA compliance requires you to back up your data at least once daily and store it in a secure offsite location.
Why traditional backups are not enough with OpenStack
Traditional backup practices and tools are inadequate for an OpenStack backup solution for a number of reasons:
- Legacy backup solutions are generally agent-based. These agents come with their own resource requirements and installation procedures. This must be planned for, resulting in a slower onboarding process. The backup process is usually disruptive and results in performance issues.
- Legacy data protection tools also often use proprietary backup formats, resulting in vendor lock-in.
- These products may also require frequent manual intervention and customization.
- They often come with a separate UI and control server, requiring additional installation steps.
- These solutions usually do not support multi-tenancy or self-service.
If you still decide to use one of these backup solutions, recognize that managing them is expensive in terms of time and effort in the long run.
What to protect in OpenStack
Protecting OpenStack can be divided into two areas of focus.
OpenStack cluster components
Cluster components are OpenStack services such as Nova, Cinder, Glance, and Neutron. Depending on how you create the cluster and what components are enabled, it is a good practice to back up the configuration files of each component and its database. It is also a good idea to back up the log files of these components.
OpenStack tenant workloads
Tenant workloads are instances where applications run. Protecting a workload involves backing up the instance, associated volumes, network configuration, metadata, logs, etc.
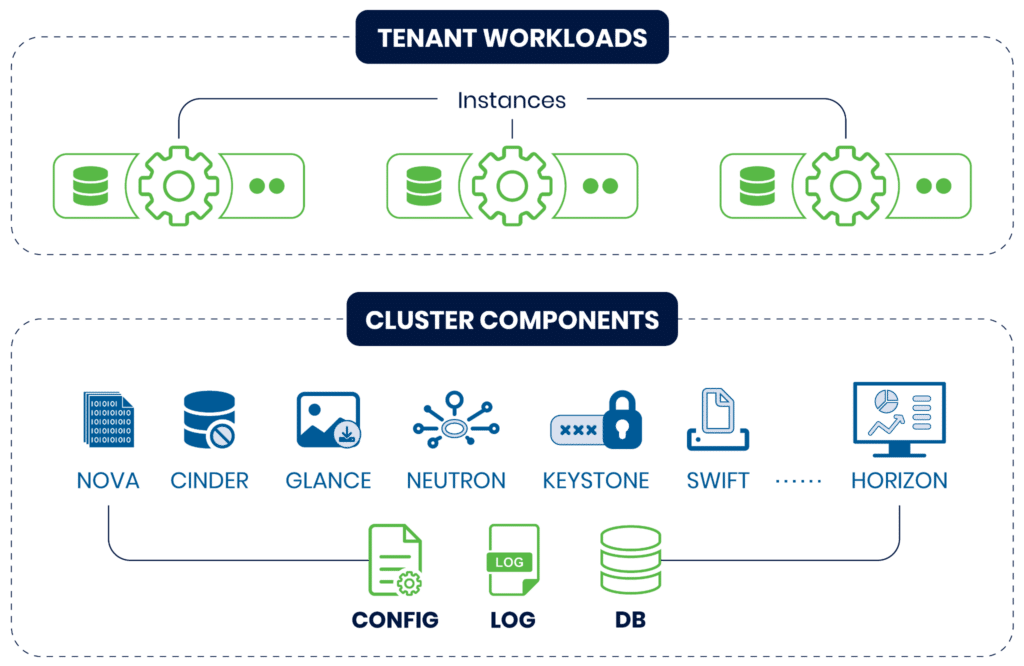
OpenStack Components and Workloads
Comparing OpenStack backup solutions
Here is a quick comparison of four popular OpenStack backup solutions: CommVault, Freezer, Storware, and Trilio.
Feature | CommVault | Freezer | Storware | Trilio |
Agentless communication | No | No | Yes | Yes |
Multi-tenancy support | Yes | Yes | Yes | Yes |
Application-centric backups | Yes | No | No | Yes |
Encryption | Yes | Yes | No | Yes |
Point-in-time snapshots | No | Yes | No | Yes |
Storage support | – | SWIFT, SSH, LocalFS | SWIFT | SWIFT, NFS, S3, Ceph |
Horizon integration | No | Yes | No | Yes |
Support | Tiered levels. Not all are 24/7 | Community support, Documentation | Community for free/freemium users, Email support for trial/paid users | Standard and Premium Support, Slack, Documentation, Reference APIs |
Trilio for OpenStack backups
Trilio for OpenStack (T4O) provides many of the features and capabilities you should look for in an OpenStack backup solution. It is a mature product that natively integrates with OpenStack to provide self-service data protection and faster data recovery.
One of Trilio’s key features is its application-centric backups. Trilio leverages the native OpenStack APIs of components such as Nova, Neutron, Cinder, Glance, etc. and captures a point-in-time backup consisting of data and metadata using an incremental approach.
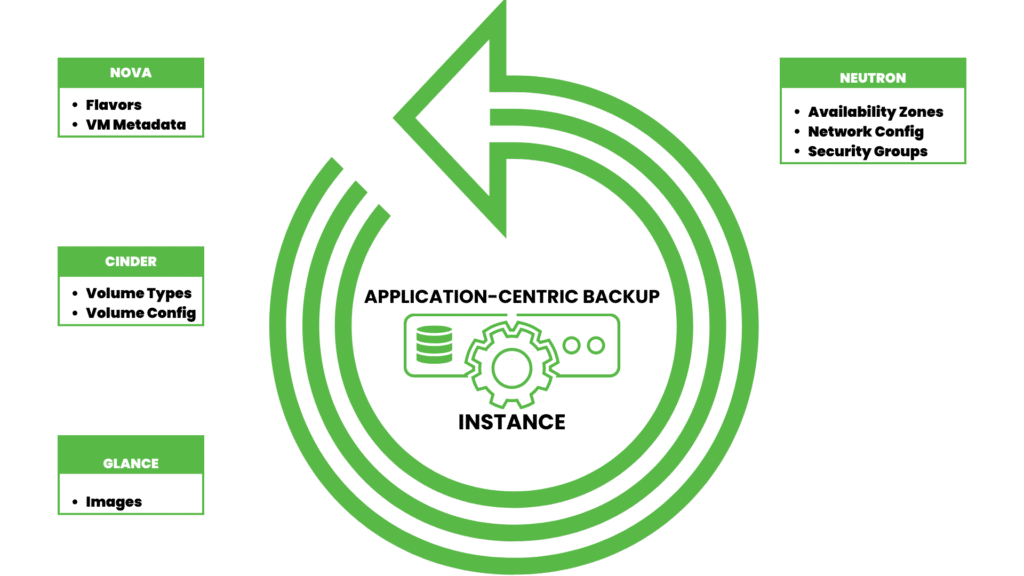
Trilio’s application-centric backups
For example, a VM backup through Trilio includes metadata such as information about the IPs associated with the VM, security groups, flavors, networks that the VM is attached to, volumes attached, and the ID of the VM.
After installation, Trilio integrates as a native component of Horizon, making backup operations part of the unified view of OpenStack operations. It also implements tenant-level control using the existing role-based access control (RBAC) methods that OpenStack uses. In short, it works out of the box with OpenStack. For example, Trilio’s integration into the Horizon UI makes it effortless for backup administrators to create backup workloads and define backup policies.
Apart from the usual backup and recovery use cases, here are some other use cases where Trilio can help.
One-click restore
One-click restore is a nifty feature of Trilio; as the name suggests, it allows you to use a single click to restore entire workloads (one or more instances) to the state they were in when they were backed up. It restores everything associated with the instances, including storage, image, flavor, network configuration, etc.
Selective restore
The selective restore feature gives more control over the restore process. Selective restore allows you to select which instances (in a backup workload) to restore, set a different name for the instance, choose which network and storage domain to use, restore to a different cluster, change flavor, etc.
OpenStack upgrades
OpenStack is a complex piece of software, and upgrading OpenStack, especially between multiple versions, can introduce changes that break a previously working cluster, such as deprecated APIs, deprecated features or unsupported drivers, resulting in an unfunctional cluster. Whether you follow an in-place upgrade or parallel upgrade, use Trilio to protect workloads before the upgrade process to ensure recoverability or to be able to migrate.
Migration
Trilio supports multiple migration scenarios, such as tenant-to-tenant migration, availability zone migration, distribution migration (migrating from upstream to Red Hat OpenStack), and version migration (for example, from Yoga to Zed).
Trilio also supports live migration of production workloads from VMware to Red Hat OpenStack with minimal impact and maximum flexibility. It can identify and pre-stage VMs before moving the data.
You can read more about how to migrate workloads from VMWare to OpenStack in Trilio’s comprehensive guide.
OpenStack backup best practices
When choosing and implementing an OpenStack backup solution, implement these best practices necessary for cloud-native workloads:
- Start with clearly defining your organization’s RPO and RTO in case of data loss, general failure, or disaster. These are important considerations for your backup policy, storage requirements, how much data loss is accepted, and how fast can you recover. For example, instances with critical data may have higher backup frequencies than other data types.
- Platforms like OpenStack are application-centric, so they benefit from application-centric backups, which back up not only the instance and its data but also tenant resource dependencies such as metadata, configuration, and network information.
- Once you have finalized the backup policies, create the actual backups. Save them in a storage backend that aligns with your data protection needs, compliance, and cost. Use automated approaches such as scheduling backups.
- Continuously improve your recovery plan by testing different scenarios and adjusting your RPO and RTO.
