Here, the developer defines the desired state of the Nginx deployment and service in YAML files. These files are then committed to a Git repository. A GitOps operator (like Argo CD or Flux) continuously monitors the repository and automatically applies the changes to the Kubernetes cluster.
It’s important to note that the GitOps approach isn’t limited to application deployments. The declarative principles can also be applied to manage the entire Kubernetes cluster configuration, including namespaces, network policies, RBAC roles, and more. In a disaster recovery scenario, this allows for the automated re-creation of entire cluster configurations from Git. A typical recovery workflow could involve automatically provisioning new clusters, followed by using GitOps tools like Argo CD or Flux to redeploy the entire cluster configuration and then stateless applications. Stateful applications can also be recovered using dedicated backup and recovery tools like Trilio.
Enterprise-scale deployment orchestration
Built-in Kubernetes task management capabilities like jobs and cron jobs offer basic scheduling but lack the orchestration sophistication needed for complex workflows. While suitable for simple use cases, they provide no visual pipeline representation, limited dependency management, and minimal reporting capabilities.
When you outgrow native constructs, look for CI/CD tools that can help you implement processes that require approval gates, complex testing sequences, or deployment coordination across multiple services. With rising complexity, you would need formalized change control and coordinated releases that simple deployment pipelines cannot provide.
GitOps improves upon traditional CI/CD by using cluster agents that continuously pull the desired state from Git repositories rather than pipelines pushing changes to environments. The model provides several advantages:
- Your repository always reflects what’s running (or should be running).
- Clusters don’t expose credentials to external systems.
- Agents automatically correct drift between the desired and actual state.
ArgoCD and Flux are two leading platforms in this space that take different approaches to implementing GitOps principles.
ArgoCD enforces the desired state through continuous reconciliation loops. Rather than maintaining separate manifests for each cluster or namespace, you can define templates through ApplicationSets that automatically generate appropriate configurations based on cluster, environment, or custom parameters. Its declarative promotion workflows allow you to automatically advance applications between environments based on customizable criteria and approval gates, a capability that native Kubernetes lacks without significant custom development.
Flux embraces a fully Kubernetes-native control plane with multiple specialized controllers (source-controller, kustomize-controller, helm-controller, and notification-controller) that can be installed independently based on requirements.
The idea behind this design principle is to eliminate separate management overhead, but with the subtle cost of fewer visual deployment insights than ArgoCD’s rich UI.
If you are already accustomed to Kubernetes internals, the Flux model can be very intuitive.
Monitoring and logging
You get only rudimentary observability capabilities with Kubernetes out of the box, leaving a need to bridge significant gaps in production environments. When troubleshooting issues, kubectl logs will only show the output from currently running containers. Once a pod restarts or is rescheduled, that valuable diagnostic information disappears forever. Similarly, kubectl top shows just a momentary snapshot of resource usage without any historical data to help admins with trend analysis or let them plan capacity effectively. In addition, for application-specific metrics like request latency, error rates, or business KPIs, Kubernetes provides no native collection mechanism at all.
Major cloud providers now support Prometheus and Grafana through managed service offerings. The broader Prometheus ecosystem includes several integrated components that collectively help you build a strong monitoring foundation through its pull-based architecture and automatic service discovery. For deeper visibility, you can instrument your application code with Prometheus client libraries to expose key performance indicators via HTTP endpoints that Prometheus can scrape.
You can also create a tiered dashboard approach similar to the following by pairing Prometheus with Grafana:
- Build infrastructure dashboards showing cluster-wide resource utilization.
- Develop service-specific dashboards for each application team.
- Create executive dashboards that translate technical metrics into business outcomes.
Automating the deployment and maintenance of these tiered dashboards requires declarative configuration. Unfortunately, native Kubernetes mechanisms fall short when monitoring resources. To apply the same GitOps principles to your observability stack that you use for applications, implement the operator pattern to bring monitoring into your existing Kubernetes workflows. When a development team deploys a new service, the team can include the corresponding ServiceMonitor resource that defines exactly how their application should be monitored. The Prometheus operator automatically detects this resource and reconfigures Prometheus accordingly without requiring any manual intervention.
Adding logging to your observability strategy
While Prometheus excels at capturing numerical metrics, it’s not designed for handling logs. For complete observability, the Elastic Stack (formerly known as “ELK” for Elasticsearch, Logstash, and Kibana) adds up to your overall observability strategy and works best when:
- You need to perform full-text search across application logs.
- You want to analyze unstructured or semi-structured log data.
- You require complex log parsing and transformation capabilities.
- Your troubleshooting process involves correlating events across multiple systems.
- You need to retain logs for extended periods for compliance or security analysis.
Also deploying Fluentd as a DaemonSet ensures that logs from every container on every node are captured, enriched with Kubernetes metadata, and forwarded to Elasticsearch. The metadata enrichment is particularly crucial as it transforms raw container logs into contextualized information that reveals which namespace, deployment, or service generated each log line.
However, it’s important to note that the logging landscape continues to change. For instance, starting with OpenShift Logging 5.6, Vector has replaced Fluentd as the default log collector. Vector (built in Rust) is used for being a high-performance, vendor-neutral observability data router that offers considerable advantages in terms of resource consumption and flexibility.
Although use cases may call for a mix of other tools, the most effective implementations integrate the tools focused on similar aspects of monitoring. For example, when an alert fires in Prometheus, include direct links to relevant Kibana dashboards showing logs from the affected services. This integration dramatically reduces mean time to resolution by providing both signals that something is wrong (metrics) and diagnostic information to understand why (logs).
Security and compliance
Kubernetes standard security primitives provide essential foundations for protecting your applications. Still, without additional guardrails, Kubernetes will readily deploy containers with critical CVEs, outdated libraries, or malicious packages. Perhaps the most challenging aspect is integrating security visibility with your overall observability strategy; native Kubernetes controls provide no standardized way to export security metrics into monitoring systems like Prometheus.
Specialized security tools like Prisma Cloud, Red Hat Advanced Cluster Security (ACS), Falco (from Sysdig), and Snyk directly address Kubernetes security limitations by identifying vulnerabilities the platform misses and seamlessly exporting these critical metrics into your Prometheus and Grafana ecosystem for immediate remediation. When security data lives in the same observability pipeline as operational metrics, you gain powerful correlation capabilities. For example, you can immediately see if a performance degradation event coincides with suspicious container activity or a newly deployed version introduces both reliability issues and security vulnerabilities.
Snyk addresses the vulnerability detection gap by scanning images before deployment and monitoring deployed workloads for newly discovered vulnerabilities. Unlike manual kubectl commands, Snyk continuously tracks vulnerabilities across your entire application inventory, prioritizes them based on actual exploitability, and often provides automated fixes.
Prisma Cloud extends the Kubernetes security model with behavioral monitoring and runtime protection. While Kubernetes can enforce a container running as a non-root user, Prisma Cloud can detect when that container suddenly attempts to modify system files or establishes unexpected network connections (activities that might indicate a breach but would go unnoticed by native controls).
That said, be careful of overcomplicating your cluster’s security posture with redundant tools when investing in proper configuration of Kubernetes’ native controls would have helped. If it’s just about plugging the security gaps that native controls cannot provide, consider combining native Kubernetes security features with specialized tools. For example:
- Implement all appropriate native controls (e.g., RBAC, network policies, pod security contexts) as your security foundation.
- Deploy Snyk for vulnerability management and shift-left security testing.
- Add Prisma Cloud for runtime protection and compliance monitoring.
- Integrate all security metrics into your existing Prometheus/Grafana observability pipeline.
Backup and disaster recovery
Thanks to the very resilient nature of Kubernetes architecture, it is a fair expectation that individual applications will recover from failures independently. However, entire cluster failures require separate strategies and their handling should be planned in advance.
Manual backups in Kubernetes involve creating snapshots or exporting data from Kubernetes resources and storing them in a safe location. The native Kubernetes state is stored in etcd, but backing up etcd alone is insufficient for complete recovery. Your backup strategy must account for persistent volumes, configuration, and custom resources that define your applications. This process can be done using built-in Kubernetes commands and tools like kubectl or rsync and then stored on cloud storage services such as AWS S3.
The benefit of manual backups is their availability and relatively low cost. No additional tools are required to create snapshots; if configured correctly, they can be stored reliably and cost-effectively for as long as needed. The significant disadvantage of manual backups is the overhead they generate and their relatively low scalability.
Cross-cluster recovery and migration
Platform engineering teams also need capabilities beyond simple disaster recovery within a single cluster. Cross-cluster recovery and migration capabilities enable organizations to move workloads between environments, whether it is for disaster recovery, cluster upgrades, or multi-cloud deployments.
Advanced backup solutions such as Trilio facilitate this process by capturing the complete application state in a portable format that preserves relationships among Kubernetes resources. Trilio is an enterprise-grade backup and recovery solution designed specifically to operate at the Kubernetes API level. Its architecture uses operators to orchestrate CSI snapshots, manage backup retention, and ensure application consistency through pre/post-backup hooks. This provides a declarative backup model for platform engineers that integrates with existing GitOps workflows while maintaining the separation of concerns between infrastructure and application teams.
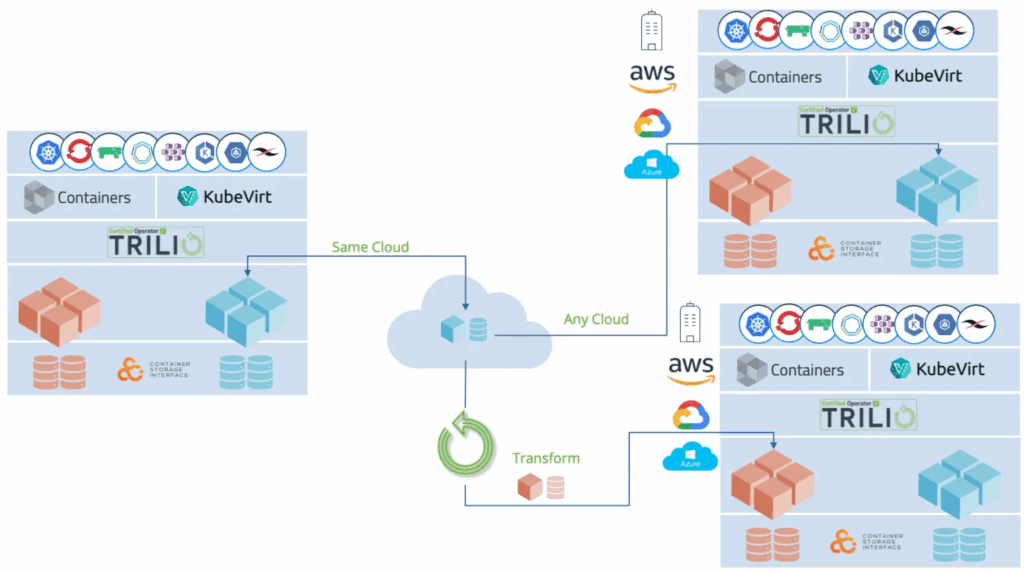
Comprehensive protection for Kubernetes operators with Trilio
Trilio captures the entire state of Kubernetes applications, including configurations, metadata, persistent volumes, databases, and custom resources. Backups can be done incrementally, only reflecting any changes made since the previously generated backup. For mission-critical workloads, Trilio’s powerful recovery capabilities support cross-cluster migrations and point-in-time recovery, allowing you to achieve ambitious RTO/RPO targets without the complexity traditionally associated with enterprise backup solutions.

